

作为一枚小白,该如何参加一场数据科学类比赛?
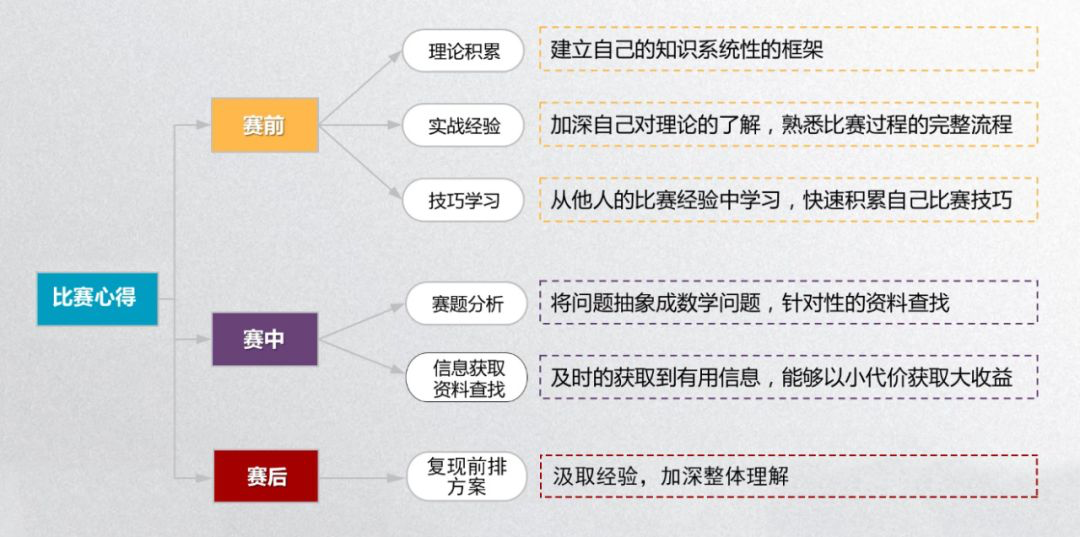
今天,方小鲸邀请到了2019中国高校计算机大赛——大数据挑战赛一等奖获得者【蜗牛本牛】团队的队长尹常攀同学来向大家分享自己的参赛心得,他将从赛前、赛中、赛后三个方面来进行分享。
赛 前
1、理论学习不管是新手,还是经常打比赛的人,都不应该忽略理论的重要性。尹同学在这里向大家推荐3本书:

- 西瓜书:周志华《机器学习》
(作为新手,理论不扎实,建议大家看看这本书)
尹同学称,当时参加比赛前他系统性地将西瓜书看了3遍,第一遍快速看看,主要了解知识点与概念;第二遍看细致一些,主要建立知识框架;第三遍之前先去复现别人的项目,再带着问题去看书。
- 李航《统计学习方法》
《统计学习方法》会比西瓜书讲的更深刻,也更难理解一点,适合进阶看。
- 《深度学习》
《深度学习》是一本经典教程,有精力的话看一下,难度比较大。
2、数据类比赛理论储备
主要划分为三个部分:特征工程、模型、模型融合。

· 特征工程
特征工程是对原始数据进行处理变换,从而抽取出特征的工作。对于特征工程,最重要的概念就是了解什么是特征。
· 模型
模型实现的是一种根据数据从已有特征携带的信息中拟合出最佳目标分布的方法。
· 模型融合
模型融合的本质:将不同模型、不同方式拟合出来的目标分布看成特征,再对这些目标进行拟合。
3、熟悉一个项目的完整流程
把理论学习完之后,后面就要熟悉一个项目。这里建议大家去到网上去复现别人已经完成的一个项目。这些项目怎么找呢?在比较知名的可以上kaggle,国内的可以上和鲸社区等。
作为新手,第一个项目要找简单具有代表性的项目,代码的可能性强,并且文档说明要比较详细。
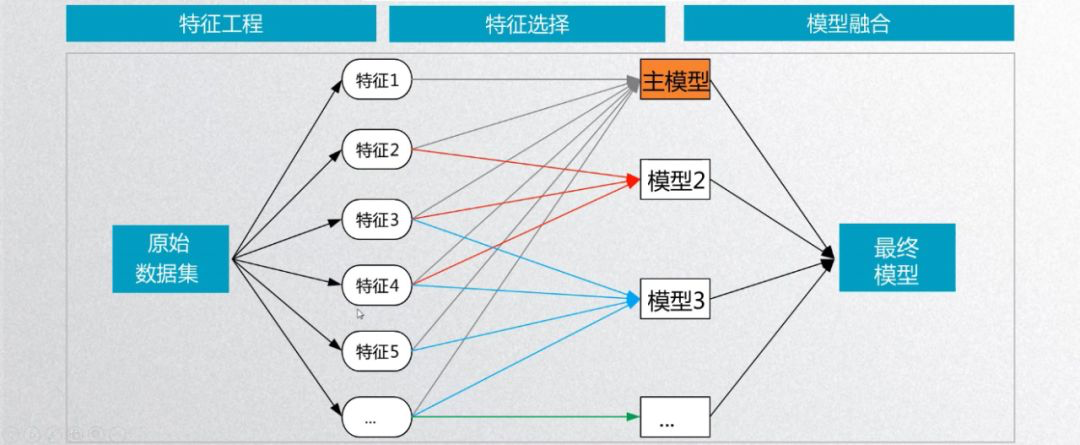
严同学认为打比赛其实是一个迭代的过程,提取一个特征,把特征输入到模型,模型训练出结果,得到反馈之后,要继续提取特征……
赛 中
1、赛题分析

比赛开始时,建议先对数据、评价指标进行分析,再定位成某一类问题,从而进行针对性的资料查找。
此次的大数据挑战赛预测点击概率,评价指标是 qAUC,是一种排序指标,用排序模型比用二分类模型就要好5‰。对于数据集,我们观察到训练集和测试集的分布不一样,且有部分数据是重合的。
经过以上分析,他们确定了思路:
对于重复的 title,使用文本信息+历史信息的特征;
对于新的 title,使用文本和搜索领域相关的特征。
2、信息获取和资料查找
比赛过程中需要不断地获取新的信息,在一些交流平台上,看别人交流哪些方法好,哪些方法不好。也可以私下里请教别人,看你遇到的问题别人有什么建议。获取到信息以后需要消化,需要查找相关资料,资料获取推荐渠道如下:

实时关注比赛交流信息,能保证参赛方向大体不会出偏差。在比赛中信息要比努力重要,不要闭门造车。
赛后总结
打完比赛,不是学习的结束。因为经过长时间的比赛,大家对赛题的思考已经很深入了,建议赛后观摩前排的解决方案和自己的方案进行对比,了解自己和别人的差距,也能从他人的方案中汲取经验,提升自己对数据科学的理解。如果条件允许的话,趁着其他团队还没有遗忘自己的方案时,建议赛后向其他团队请教,花一点时间复现出别人的工作,这样才能把握其他方案的细节。