

冠军团队由三名博士生组成,目前此方案在投论文中,之后方案代码会开源。
团队名称:没学可上
团队成员:
曾辉 博士研究生(第 4 年)
杨熹 博士研究生(第 1 年)
梁杰 博士研究生(第 1 年)
赛题任务

视频四倍超分+HDR,要求将低质量 540p SDR 视频重建为高质量、已调色的 4K HDR 视频。评测方法: 最终得分 = 25 * PSNR 项 + 25 * SSIM 项 + 50 * VMAF 项
和鲸科技赛事页面: https://www.kesci.com/home/competition/5d84728ab1468c002ca1825a/content/2
赛题分析
此次 4K HDR 比赛包含众多子任务,初步按照高频和低频两个方向划分为:高频方面,需要去噪和超分

低频方面,需要做亮度矫正、色彩增强和 SDR 转 HDR (即 inverse tone mapping)

给定时间和硬件环境下同时解决上述多个任务,需要重点考虑两个方面的矛盾:
矛盾一:高频和低频
亮度矫正和色彩增强等低频任务需要足够多的图像内容才能进行准确判断,因此训练和测试都依赖于较大的 patchsize 和感受野。在显存有限的情况下,大 patch 限制了模型的复杂度。
而去噪和超分等高频任务 pattern 更不固定,更难学,需要较深的模型和比较长的训练时间才能保证性能。
矛盾二:去噪和超分
去噪和超分关注图像高频细节,其中去噪不可避免地会损失高频信息,而超分又需要恢复高频,两个任务本身存在矛盾之处。
基于以上对赛题的分析,需要综合考虑亮度、色彩、去噪、超分等几个方面,在相互矛盾的子任务之间找到最合适的平衡点,设计最优的解决方案。同时由于本次任务所给数据退化较严重,需要仔细分析退化模式并相应地设计出有效的数据处理方案。
整体方案
数据预处理
这一部分的目的是修正数据分布,简化学习任务。处理步骤基于对数据集的观察及实验,人工得出的经验。
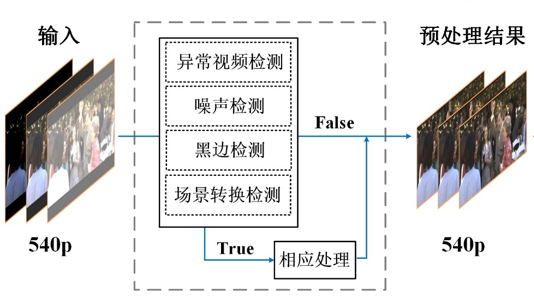
具体操作:
1.计算 YUV 空间亮度均值。这一步可以筛出严重过曝的视频(直接排除),以及视频的黑边(直接输出结果 0(SDR)->4099(HDR))。

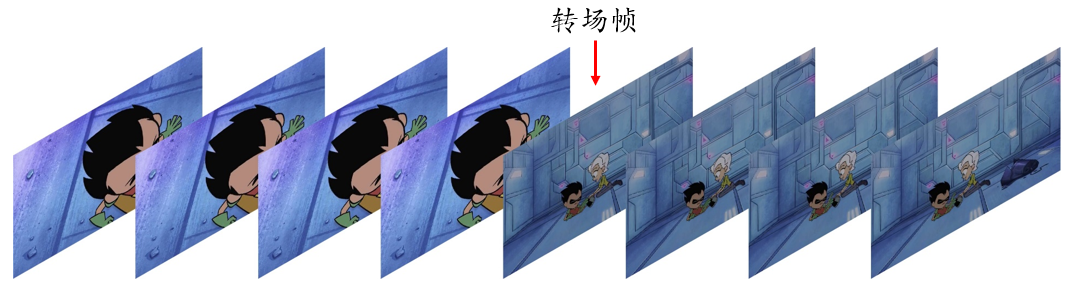
2.计算 HSV 空间直方图距离。这一步可以检测出场景的转换,提高多帧融合稳定性。
3.中值滤波去除椒盐噪声点,如果滤波后与滤波前像素值大于某个阈值,则用非椒盐噪声点替换原始值,反之不处理。


4.Non-local mean 滤波去除部分高斯噪声

模型学习
- 特征提取
1.采用大 patch(384x768)输入,确保低频任务获得足够大的感受野;2.采用一层 instance normalization 对亮度做归一化;3.提前下采样,降低显存消耗,节省计算资源。
- 特征对齐与融合
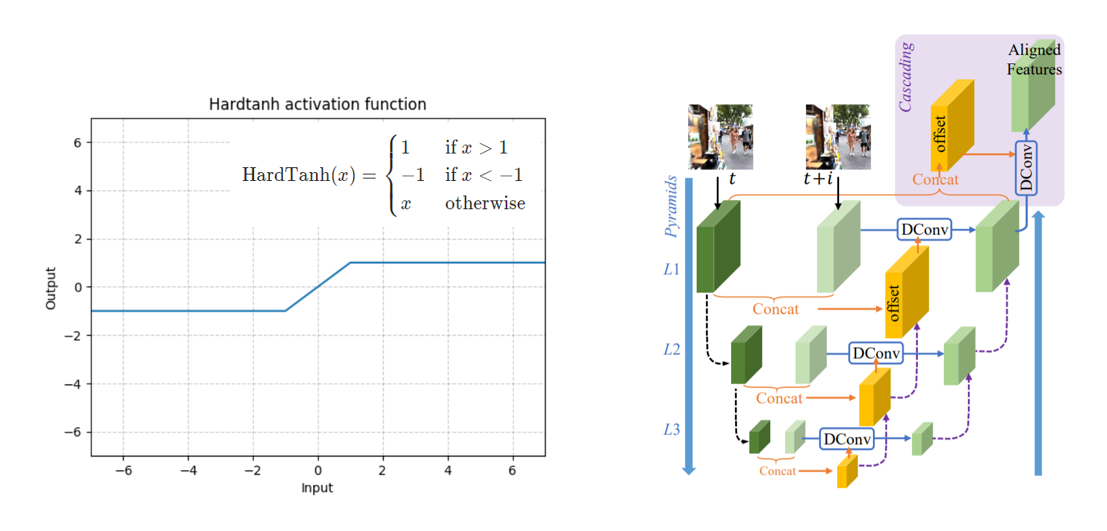
1. 采用 EDVR 中的 PCD 模块多帧对齐;
2. HardTanh 约束 offset 越界,(-32,+32);3. TV 约束 offset 平滑,利用图像空域的连续性先验。
- 低频任务学习
方案一

1.UNet 结构进一步增大模型感受野,促进低频内容学习;
2.采用 pixel shuffle 的方式上采样,减少上采样产生的 halo。
方案二
学习多个 3D LUTs 进行色彩增强
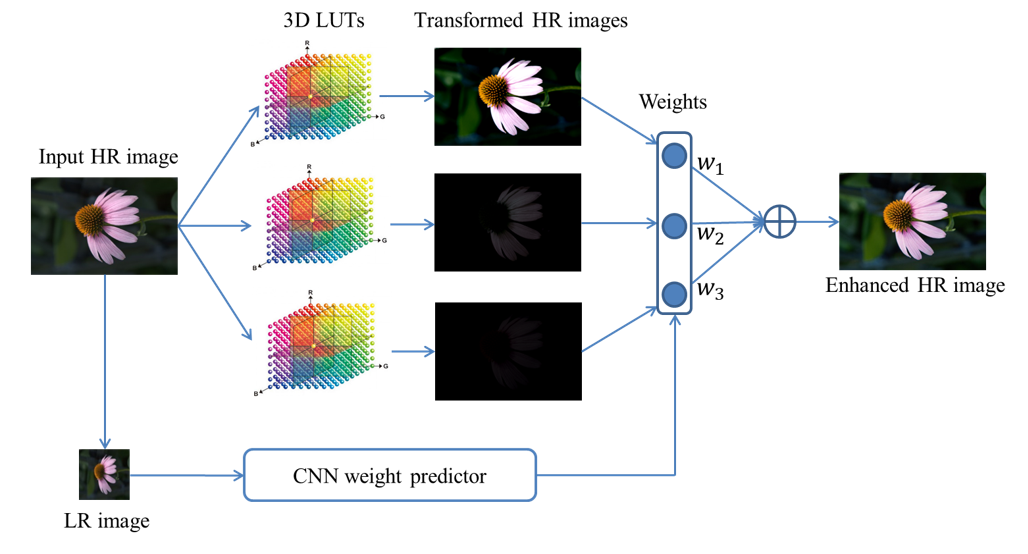
此模型优点为:仅 0.6M 参数;SOTA 性能;4K 分辨率上 200+FPS;有明确物理意义。
- 高频细节恢复
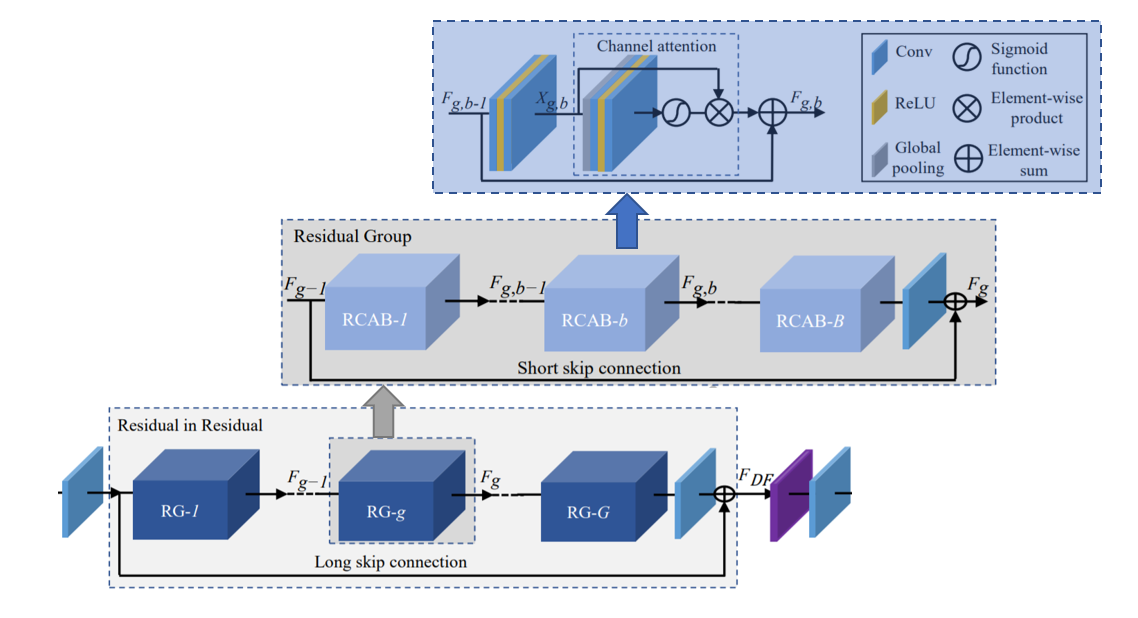
1.采用 RCAN 中的 deep residual channel attention 模块重构细节;2.不同尺度采用不同的 channel 维度,兼顾性能与效率。
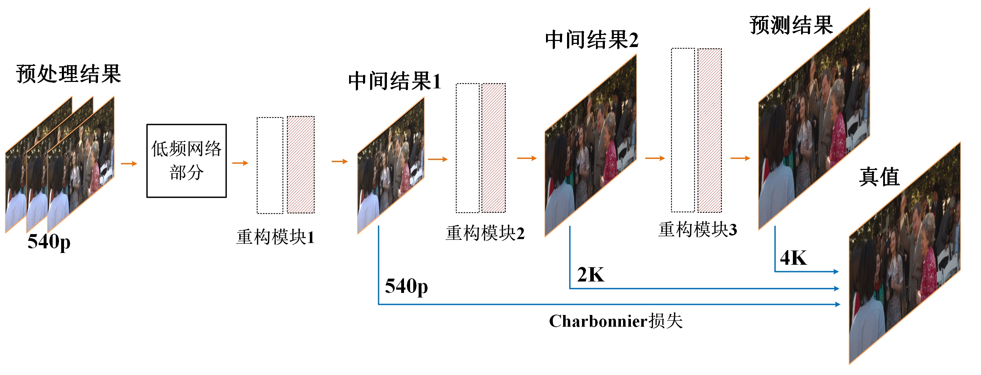
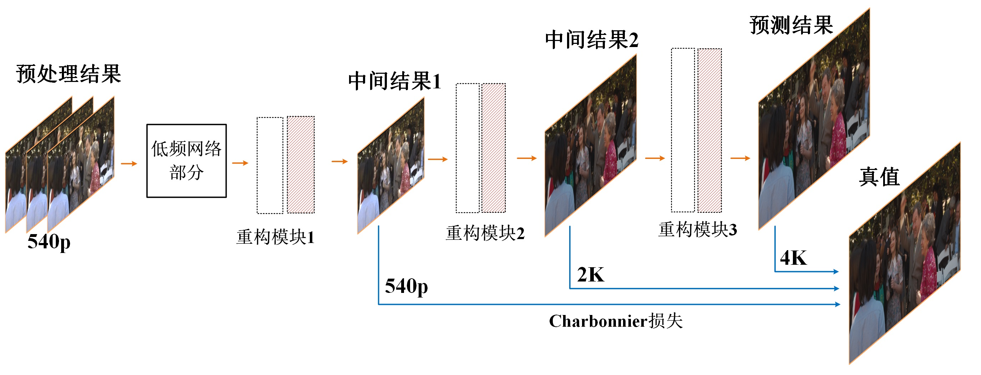
- 训练&预测
将前面几个模块串联起来之后,计算多尺度损失,这样可以提高训练效率。模型训练好之后,输出中间的预测结果。
结果后处理这一部分会对前一步的预测结果进行进一步处理,改善遗留问题,并且提升分数视觉效果
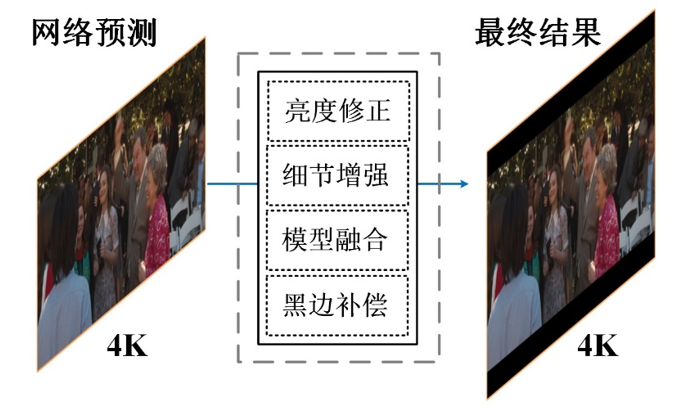
具体操作:
1.亮度修正,帧间平滑
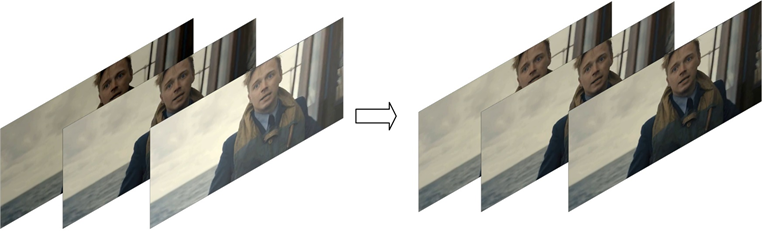
2.细节增强

3.黑边补偿

4.模型融合理论分析及实验发现,本任务中存在一些相互矛盾的子任务,需要合理设计两者之间的 trade-off 以达到最佳的结果。比如,单个模型对不同场景亮度的恢复有时候偏亮有时候偏暗,模型的去噪能力与超分后的细节保留能力之间存在着明显的冲突等等。基于以上分析,我们设计了一个双模型融合的框架,其中,第一个模型 Model_1 采用未经处理的原始数据训练,采用 512x512 的大 patch 输入,重点恢复图像低频内容,第二个模型 Model_2 使用预处理过的数据,训练采用 384x384 的 patch 训练恢复尽可能多的细节。实验发现,两个模型的预测结果在去噪、细节保留、亮度估计、色彩估计等方面均有一定的互补性,融合之后能够取得最佳效果。

参数量与复杂度分析
1.数据处理:经验为主,参数为个位数
2.模型参数总量:26.67M
3.数据处理时间:2 小时
4.模型训练时间:86 小时 (8 卡 V100)
5.测试时间:2.0 张/秒(w/o ensemble),0.5 张/秒(w ensemble)技术总结
- 方案总结
精细的数据预处理,简化学习任务,提升学习效率。
先低频、后高频、多尺度、多任务的高效学习框架。
后处理进一步提升稳定性和视觉效果。
- 创新点
细致的数据预处理和后处理提升训练的效率和测试效果。
采用大 patch 输入和引入 UNET 结构增大感受野。
改进 EDVR 框架提升模型稳定性和表达能力。多尺度 loss 约束不同频段内容,提升训练效率和效果。
双模型融合,平衡不同模型设计下去噪与超分细节之间的矛盾,同时使预测结果的亮度估计更加稳定。
- 优点
灵活:任务可分解,过程更可控,结果更稳定。
高效:模型参数少,训练时间短,收敛速度快。
稳定:结果瑕疵少,泛化能力强。
- 不足
高频模块计算代价大,无法满足实时需求。