
2023 年 3 月,科技部会同自然科学基金委启动“人工智能驱动的科学研究(AI for Science)”专项部署工作。科技部新一代人工智能发展研究中心主任赵志耘认为,AI for Science 将突破传统科学研究能力瓶颈,成为全球科研新范式。以遥感领域为例,AI 技术在图像匹配方面具备优秀的特征提取与表达能力,能从海量异构的遥感数据中获取丰富且准确的属性信息,以此挖掘目标区域的演变规律,高质量的遥感影像在灾害监测、气象、军事等诸多方面都有广阔的应用前景。
然而,AI for Science 的引入在协助遥感领域研究者解决复杂问题的同时,也为传统基础设施与工作流带来挑战。近几年,有不少科研机构在合适平台的支持下,不断探索遥感大数据与 AI 新技术融合应用的可行性方案。
中国自然资源航空物探遥感中心创建于 1957 年,是我国从事航空物探与遥感技术研究、开发及应用的专业技术中心;下设的遥感应用技术研究所是我国自然资源部地质灾害隐患遥感识别与监测工程技术创新中心的运营主体,聚焦新型航空 / 航天遥感观测技术研发,及自然资源 / 地质领域遥感综合调查与应用、工程化应用系统研发。
遥感应用技术研究所(下简称“研究所”)作为航空物探遥感领域的科技领军单位,希望打破目前遥感数据、模型算法、计算资源三者分离的局面,通过云端部署,完成对大规模数据的处理和分析,同时也希望能提高研究成果的转化效率,促进“政产学研用”的协同创新。
基于以上需求,和鲸科技旗下 ModelWhale 为研究所进行了平台级工具的私有化部署,与其共同打造了高可用、高并发的集成化开发部署平台,协助推动 AI for Science 科研范式改革。
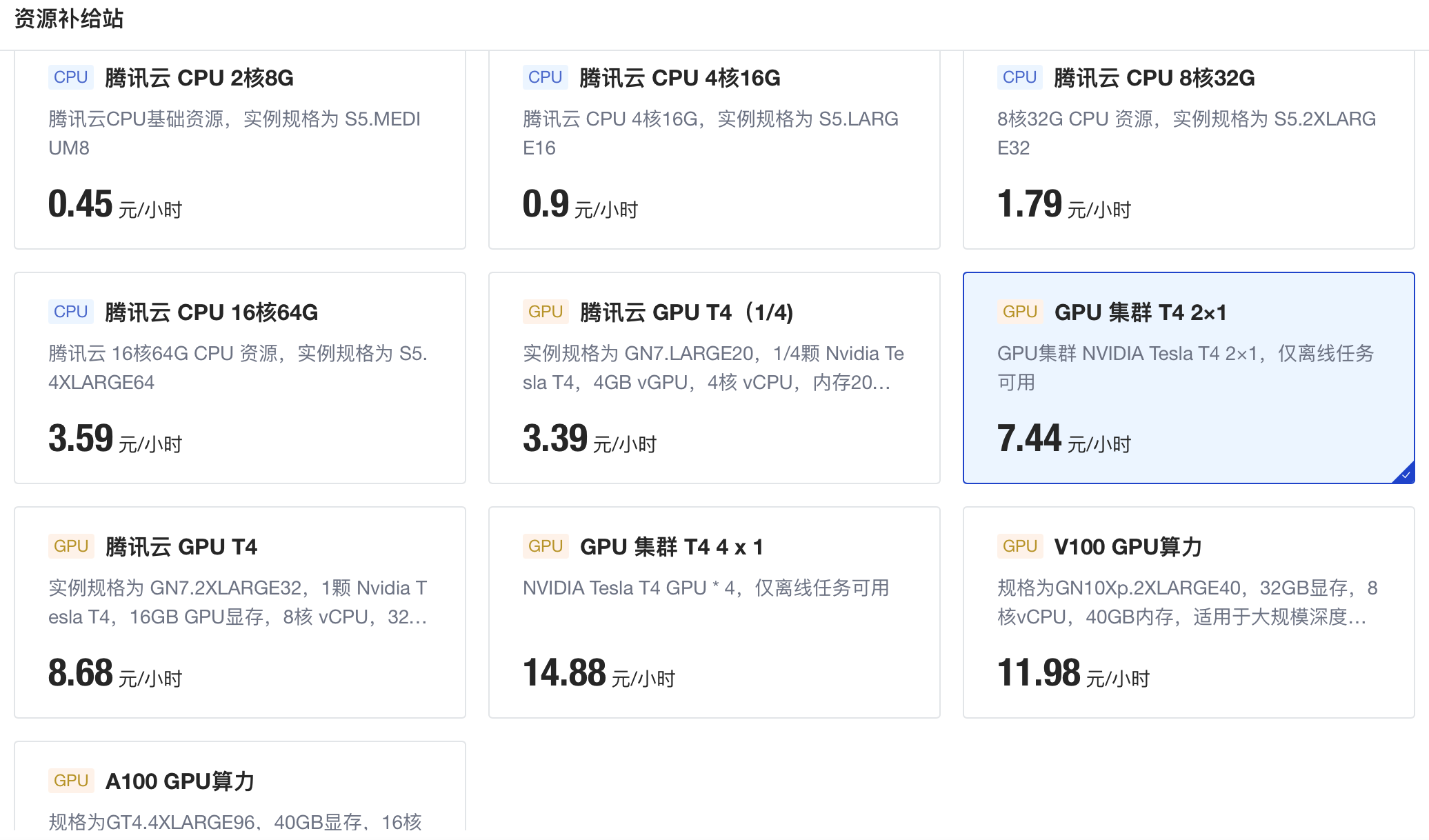
痛点一:缺少合适的计算、存储资源整合渠道
随着 AI 技术的大规模应用,研究所从过去使用 ENVI-IDL 编程进而引入了 GPU 加速,尽管提高了效率,但单机单卡和单机多卡仍是很快就满载无法使用。而目前研究者针对数据密集型和计算密集型问题普遍采用的方案是 GPU 集群,在进行尝试后,研究所发现这与其现实需求还是存在一定偏差。研究所隶属于航遥中心,内部拥有相对充足的算力资源,既希望每个研究者都能有自己的实践环境,又希望针对一些大型复杂计算问题,可以把所有计算资源集中集合起来,因此,实际的需求是一个能帮助其整合、调度存储与计算资源的平台。
解决方案:本地接入,集约管控,高效调配,GPU 集群
对此,ModelWhale 基于研究所现有的基础设施优化结构,将已有的、零散的本地计算硬件接入云端,利用平台的云原生架构进行了安全、灵活、可控的集约化运维和细粒度分割调配。
本地算力资源接入后,当需要处理大规模计算任务时,ModelWhale 可将多机多卡的 GPU 组成集群算力以供使用。GPU 集群基于 Horovod 的并行计算,可以达到成倍计算效率,适用于遥感影像多层次并行处理,这也同时为研究所在如灾害监测等具有时效性项目上进行应用提供了保障。
而在日常研究中,接入平台的算力可以根据核数与内存大小进行拆分,分配至不同研究员和项目小组。平台在项目运行时会帮助研究员自动调度匹配的机器实例,并自动加载好所需的软件环境、数据及文件。使用过程中,研究者可随时查看算力、内存、磁盘的使用情况,发现资源不够就可以通过主动发起申请获得,这一自动化流程极大地释放了研究所内部运维的压力。
最后,当项目关闭,平台将自动释放运算资源,同时将项目文件持久化存储,确保提升计算资源利用率的同时也能尽可能降低算力成本。借助 ModelWhale 强大的资源调度能力与完善的资源管理机制,研究所突破其底层架构限制,实现了对本地算力资源的能耗最小化、效率最大化应用。
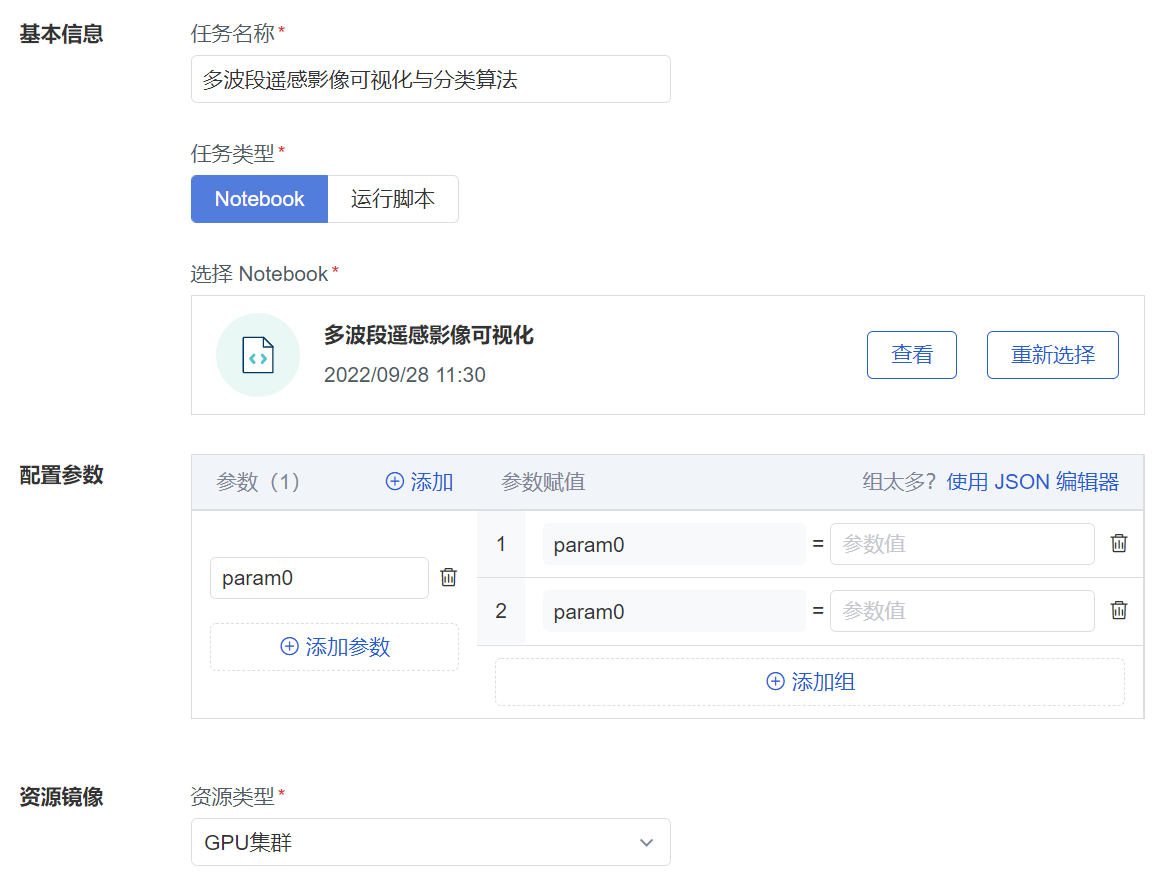
痛点二:模型调优效率较低
相较于自然图像数据,遥感数据的构成更加复杂,卫星、传感器等采集设备物理参数的不一致使得遥感数据源存在多方面差异,因此遥感实验研究过程中需要更加频繁地调整参数,并且需要将数据处理的不同结果进行可视化对比。而人为关注训练任务完成情况以保证实验的延续性既繁琐又浪费时间,因此研究所的研究人员希望利用技术和平台使这个过程自动化进行,提高模型调优的效率。
解决方案:多参数云端托管,可视化对比结果
基于 ModelWhale,针对有较高计算量的训练任务,研究人员可以采用离线托管运行 Notebook 或脚本项目文件,离线任务没有运行时长限制,自动在云端跑完,任务的发布也不会影响到研究人员继续使用电脑投入其他工作。ModelWhale 提供通知接口,研究人员可以直接从邮件或社交软件上接收训练完成的通知,而不用再时刻关注任务运行情况。
结合遥感数据特点,为了选择最有效的算法,研究人员也可以提前设置不同参数组合,同时启用多台机器完成不同参数配置下统一模型的训练,并结合 GPU 集群缩短训练时长,平台将记录模型每次训练的超参数信息,提供可视化对比报告,从更多角度对比分析模型优劣,助力研究者挑选出最合适的模型。任务运行成功后,研究人员可以保存离线运行的结果,输出结果文件,也可以随时调用训练中产出的过程文件。
ModelWhale 提供的离线训练与训练指标对比功能,构建起了高自动化、高可视化的调优流程,再结合算力资源的弹性调度,一体化缩短了遥感深度学习算法的开发周期。
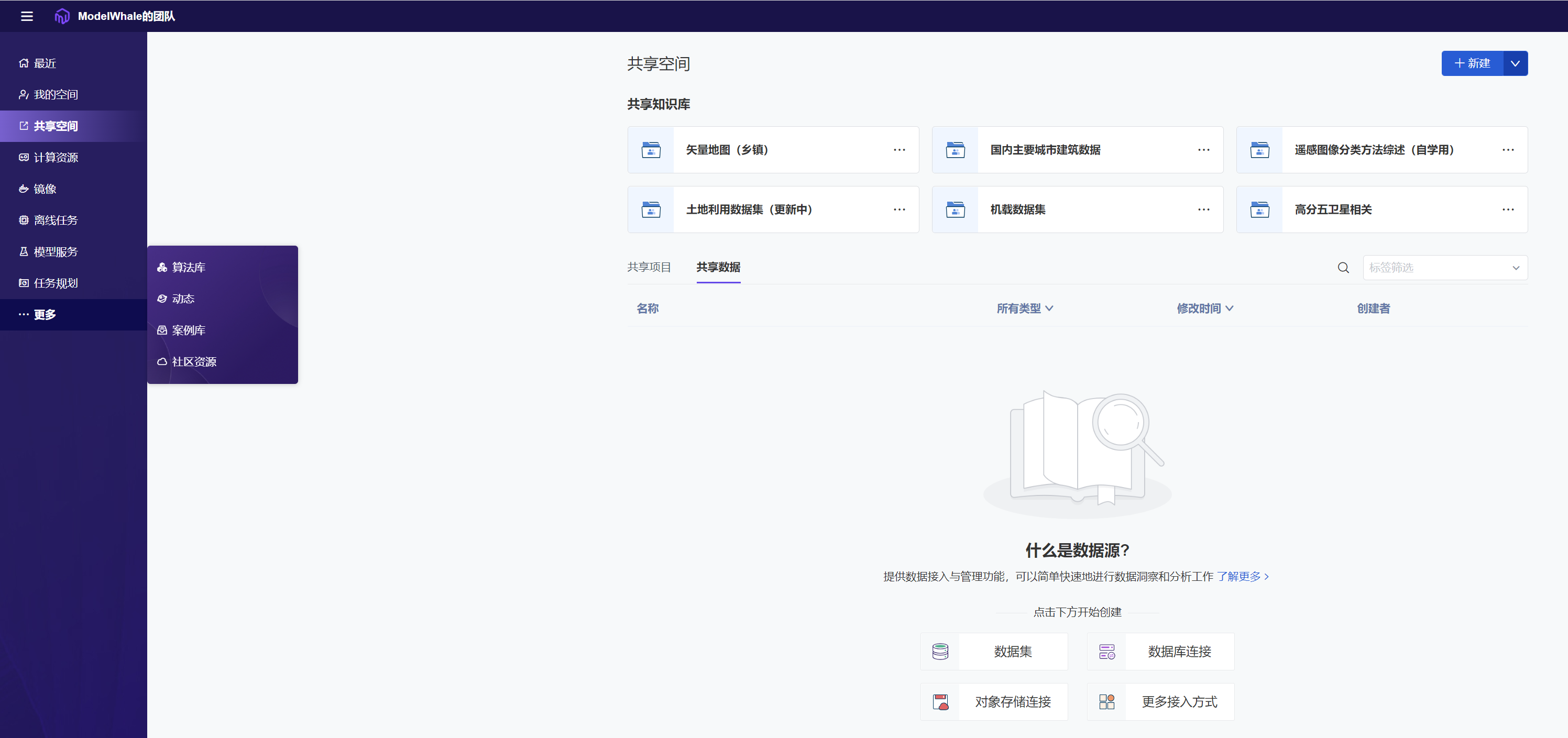
痛点三:数据与工作流的管理方式亟待更新
对于传统工作流的重构是研究所亟需解决的问题之一,规模化采用 AI 后,将工作迁移至 python 平台尽管能与深度学习高度融合,却无法对数据、算法、模型进行统一管理并形成资产积累。研究所有时需要每天接入几百景数据,庞大的数据量使得数据准备阶段的工作十分繁琐。另外,即使后期形成了算法模型,遥感数据分析模型的部署和运行又可能依赖于不同的软硬件环境,包括操作系统、编译器、支持库等等,按需部署具有一定难度。
解决方案:数据、算法到模型的研究对象一站式全流程管理
针对上述问题,ModelWhale 以高集成度的开发工具,助力研究所搭建起高效工作流。
基于平台,研究所首先可以多种方式接入存放在本地、数据库、对象存储以及 NAS 空间中的各类数据并统一管理,平台标准化的协同流可支持研究团队内成员同步使用各类生产资料分析研究。其次,研究人员可根据遥感数据分析模型运行和部署的需求自定义云端镜像环境,所定制的环境皆可基于平台规范描述,只需将镜像分享给他人或帮助他人重构即可从环境层面保证算法模型的异地复现。而遥感作为一门技术,常被应用于不同领域问题的解决,因此对于开发完成的模型,平台还提供了一键自动化部署,简化模型从开发到应用的复杂度。
对于项目流程管理,ModelWhale 支持将课题拆解成多个阶段任务进行宏观管控,各个领域的研究者可在细分任务中查看进展情况,并明确每个人的职责分工。任务结果可以多种形式提交,其他成员在线同步查看,这有利于团队内部的信息同步,把控整体节奏,提高研究课题的交付效率。
最后,研究人员可以选定运行时的分析环境、数据集、算法代码版本,将生产要素整合并补充一定文字说明后,沉淀至组织内部的成果库中,便于后期随时复现。另外,团队内部的项目、数据、文件、视频皆可用文件夹与标签的形式进行整理,并沉淀至团队的知识库中,供所有人调取使用。
结束语
在技术革命与顶层政策的引领下,科研界正给予人工智能越来越多的关注。未来,AI 技术或许会成为一种基础服务,像作用于遥感数据的处理、应用一样,拓宽各领域科学研究的方式方法、改变科研工作者间的协作模式。
在此纳新求变的过程中,和鲸科技旗下的 ModelWhale 科研版聚焦数据驱动研究的协同创新,是以推动 AI for Science 科研范式改革、加强有组织科研为己任的数字化基础设施:关注从数据、算法到模型等研究对象的一站式全流程管理,从基础设施层面提升科学研究的可复现性,帮助营造协作协同的良好科研生态;基于 FAIR 原则与开放科研理念为数据等研究生产资料提供安全、完善的公开共享门户与在线交互工作台;异构融合、集约管控、按需分配、敏捷响应,强大的算力调度管理使个人电脑调用 LLM 大语言模型成为可能,也使算力资源在组织团队内发挥最大可用性;引入 ModelOps 理念,助力大模型全生命周期管理。
ModelWhale 科研版覆盖地球科学、生物医学、人文社科等专业领域,且已将最佳实践落实于国家气象信息中心、中国自然资源航空物探遥感中心等国家级科研机构,希望能为每一位从事数据创新研究的开拓者及其团队提供支持。任何相关需求,都欢迎您进入 ModelWhale 官网 注册体验,或扫描下方二维码、联系产品顾问与我们展开交流。
