
今年三月,国家科技部会同自然科学基金委正式启动“人工智能驱动的科学研究(AI for Science)”专项部署工作。数据驱动的科学研究长期以来面临诸多困境,针对传统科研工作流中过度依赖人类专家经验与体力的局限性,AI4S 旨在基于科学数据与算力支撑,通过人工智能的方法,进行计算密集、高效迭代的科学探索,为科研工作带来新的突破。
然而,随着科研范式的不断升级,传统基础设施已逐渐不能响应新兴 AI for Science 所需的软硬件支持。本文将聚焦“从数据、算法到模型的研究对象一站式全流程管理”,为各领域研究团队介绍数据科学协同平台 ModelWhale,以期为由人工智能驱动的科学研究提供助力。
一、科研期待与现状
科研期待:项目能有完整的生命周期,结项不是项目的终结,后续能够复用是项目生命的存续
实际情况:“作坊模式”而非“平台科研”,无法串联团队工作,成果复现效率低,项目生命周期短
对既往研究成果进行复用以赋予项目完整生命周期中的“复用”定义十分宽泛:可以是复用既往项目中的“中间成果”,譬如仅仅一个代码片段;也可以是“阶段性较为完整的成果”,譬如一个模型或搭建完成的一个镜像;还可以是对于某一类项目较为流程化、规范化的“研究范式”。
同时,此类“复用”是跨时间、跨人员的。然而事实上,由于项目研究成果缺少系统的归纳管理,加之项目组人员时有更替,随着时间的流逝,极容易忘却之前的研究成果,即使记起、有复用的打算,也很难将其翻找出来、辅以配套环境完整复现。即使大家都赞同,合理复用从长远能够节省大量时间,为避免当下的麻烦,项目进行过程中大部分相关人员还是会选择重头再来。
二、人工智能驱动科学研究的全生命周期管理
ModelWhale 聚焦从数据、算法到模型等研究对象的一站式全流程管理,从基础设施层面提升科学研究的可复现性,帮助营造有组织科研的良好生态。
项目从零生产
01 多源数据接入、管理
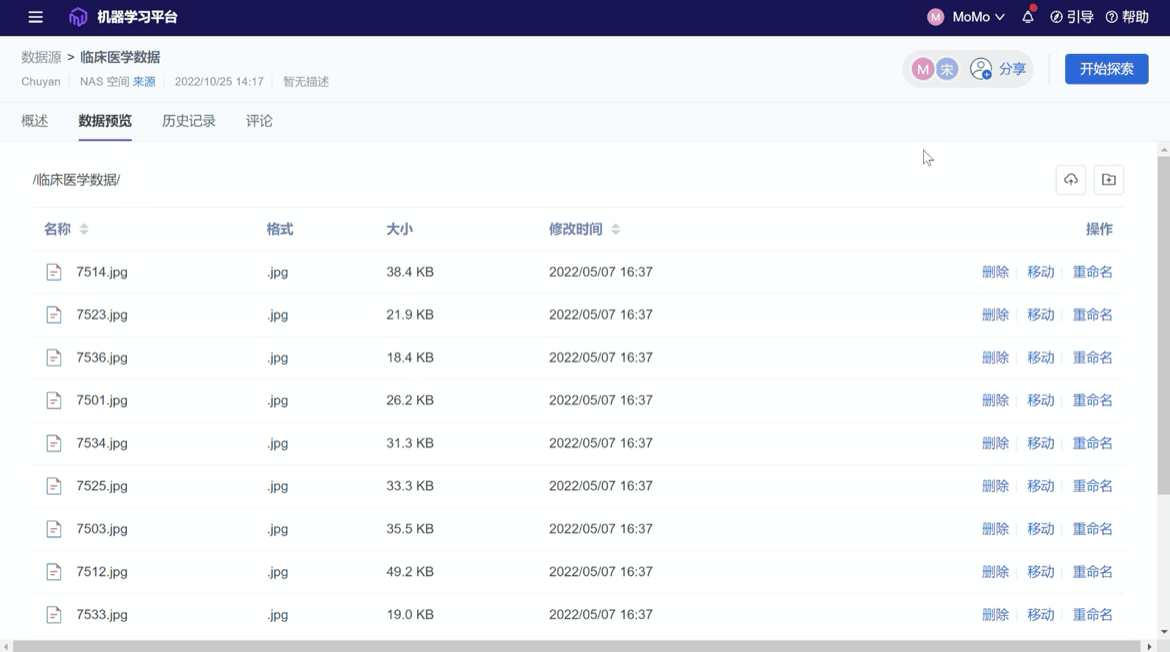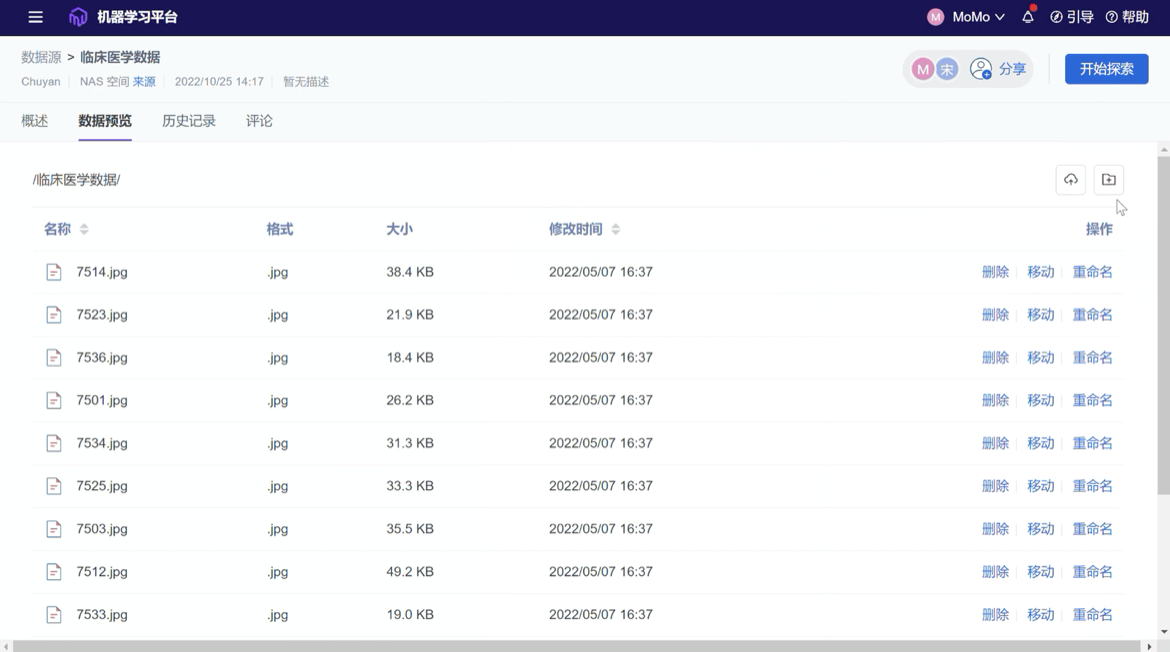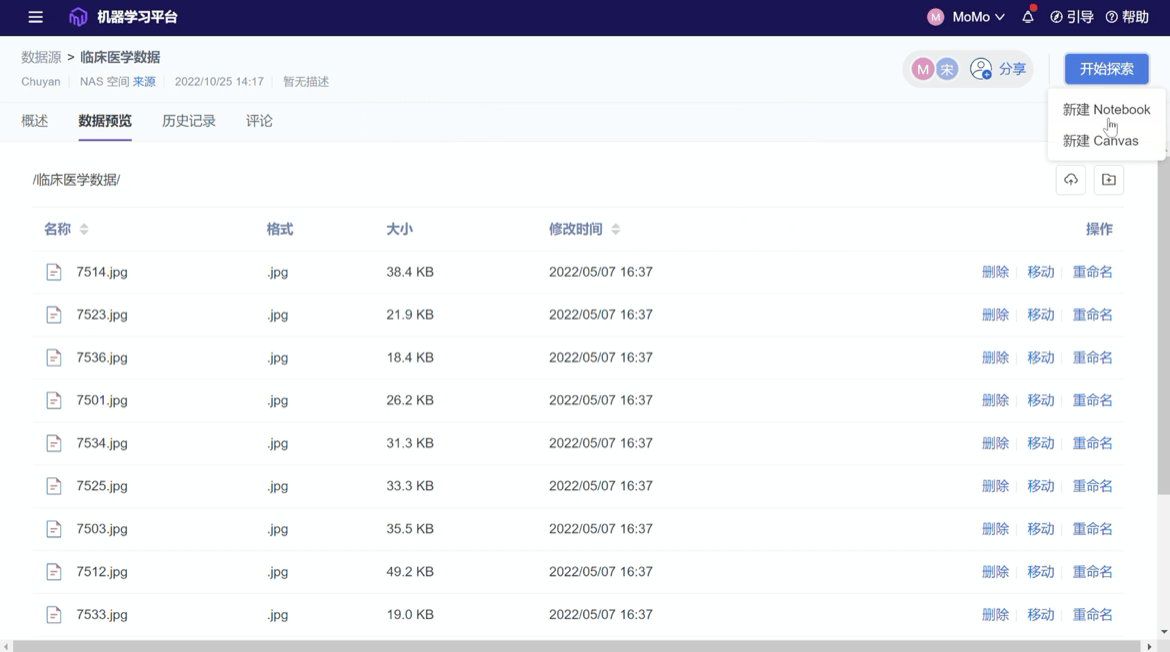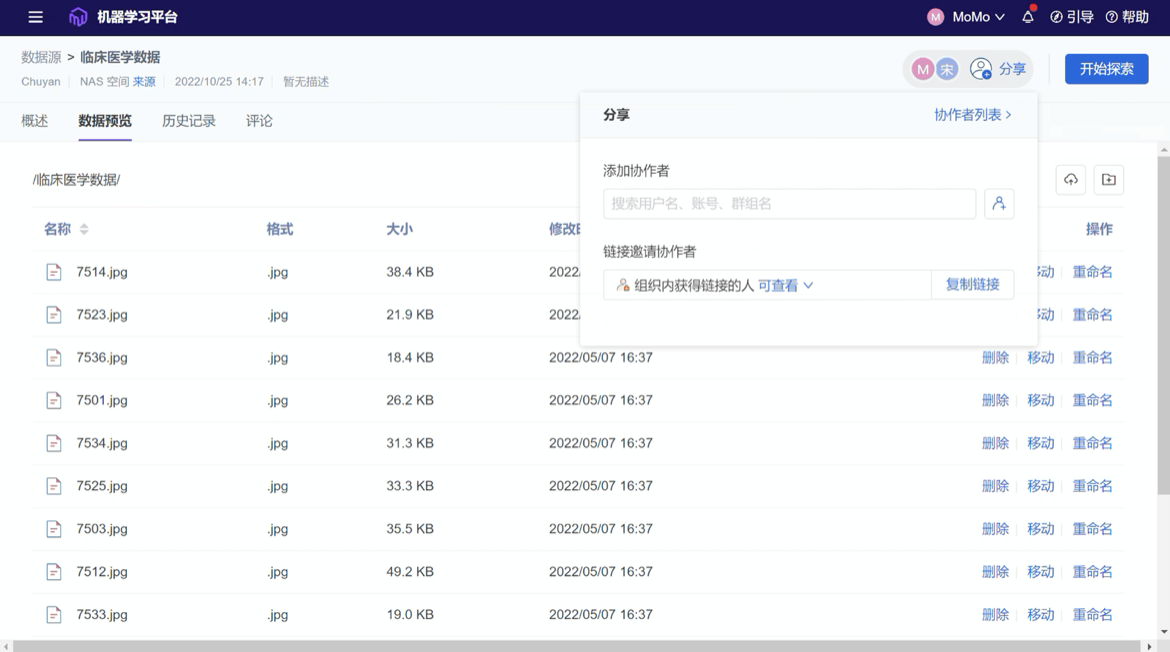
数据驱动研究的地基便是数据本身,而部署于传统基础设施的数据驱动研究在数据管理上主要依赖的还是人力。而通过 ModelWhale,在保证数据安全的前提下,研究者们不仅能够创建不同类型的数据源,例如数据集、数据库连接、对象存储连接、NAS 空间、标注数据等,更是能够对相关数据源进行概述、标识、版本管理、评论及分发共享。ModelWhale 为研究者们提供的数据接入与管理功能就是要为数据驱动研究打好基础,令广大研究人员不必再为数据管理的底层繁复工作浪费时间。
02 即开即用免装包
解决了数据问题便从零生产项目,而生产项目的第一步,往往是装包搭建环境。作为云端数据科学协同平台,ModelWhale 提供 Notebook 交互式、Canvas 拖拽式、CloudIDE 三种云端分析环境,并支持 Python、R 等数种编程语言,适配研究者们不同的编程需求与习惯;另外平台内已配备多种通用与特定学科镜像,新建项目时直接选定即可,真正做到即开即用——打开 ModelWhale,不需要配置任何环境,即可开始项目研究,省时省力。
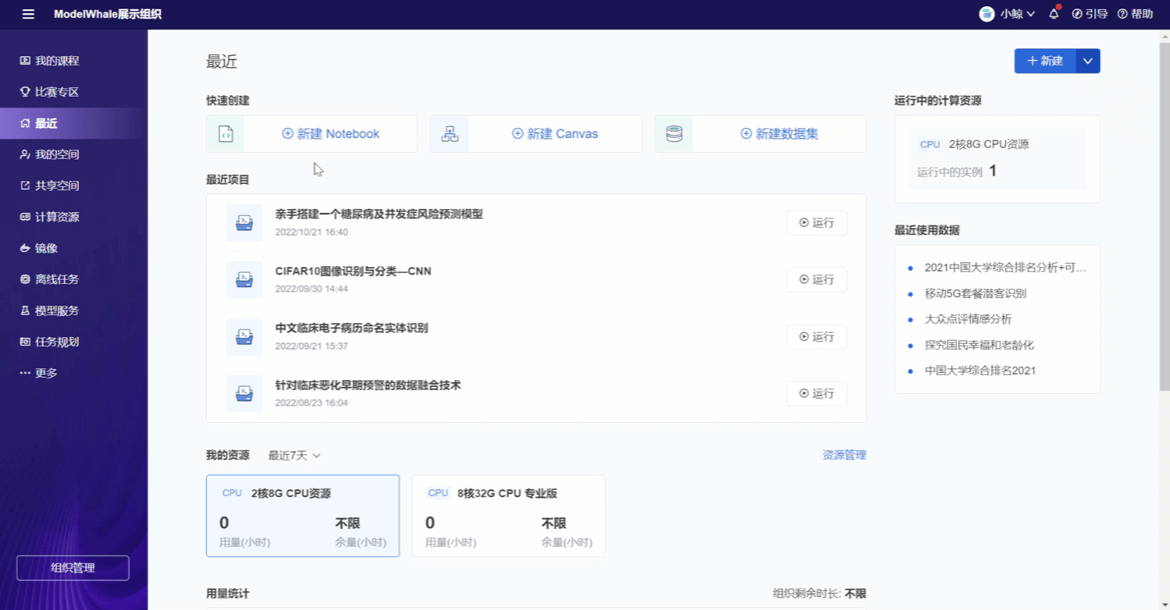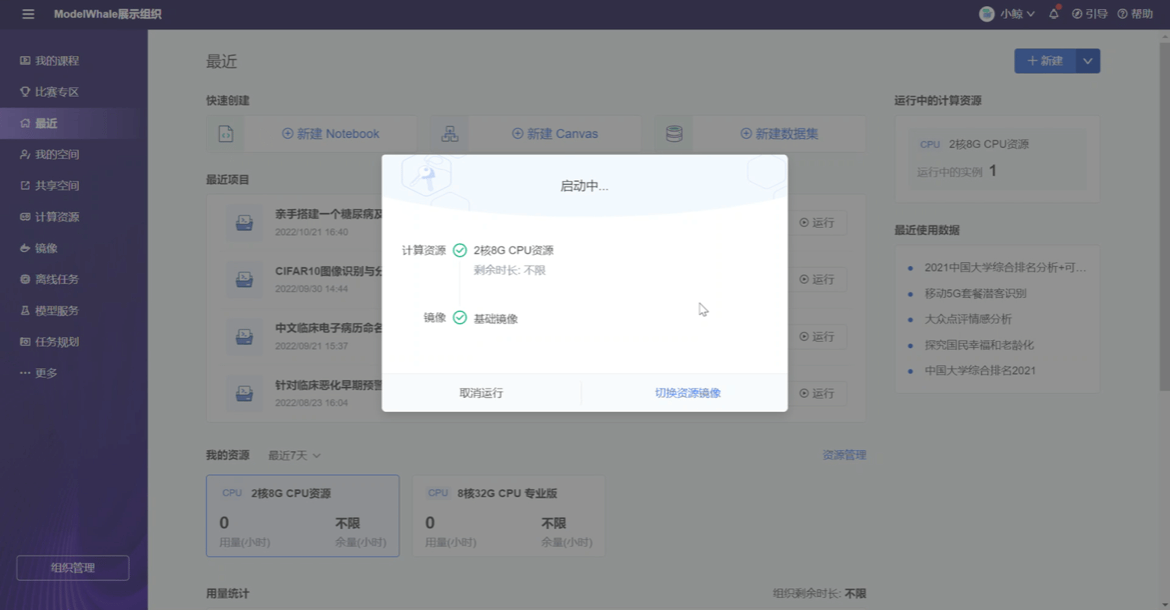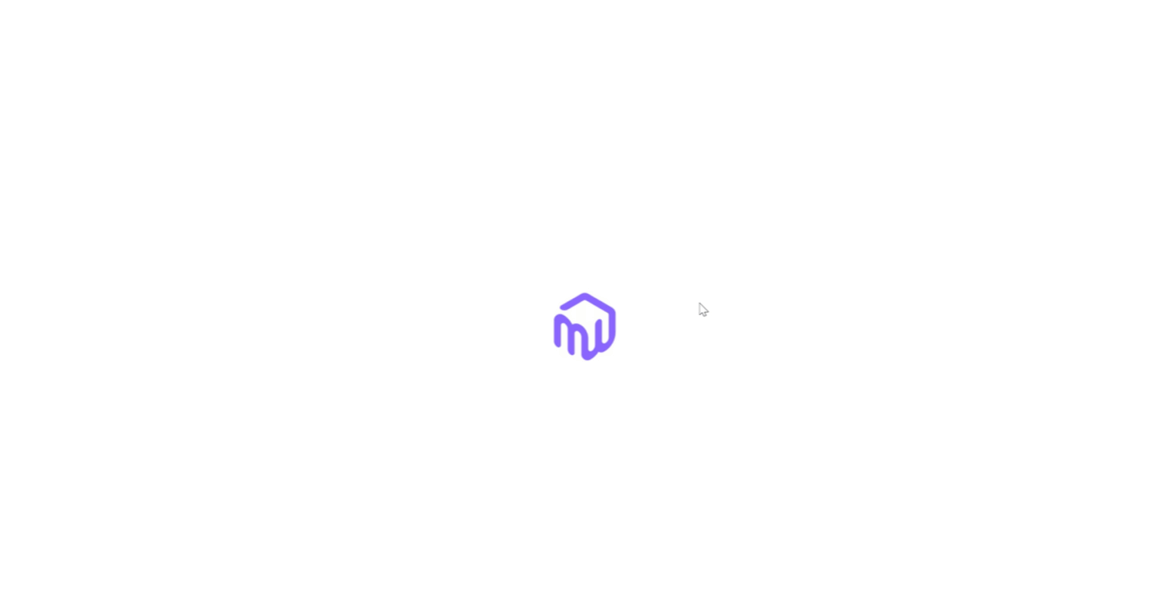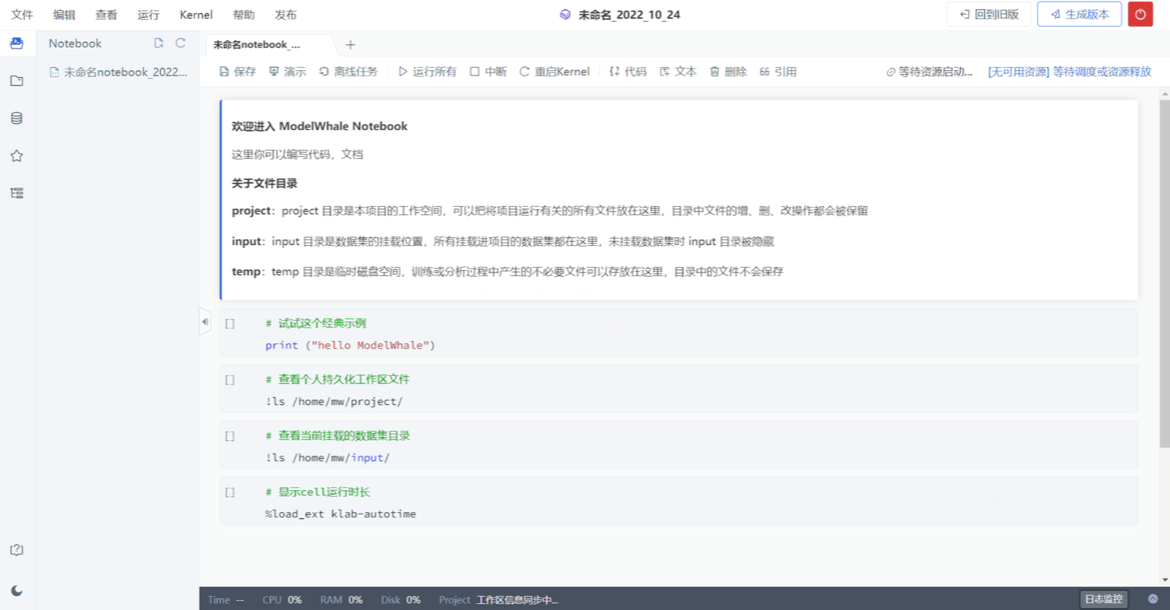
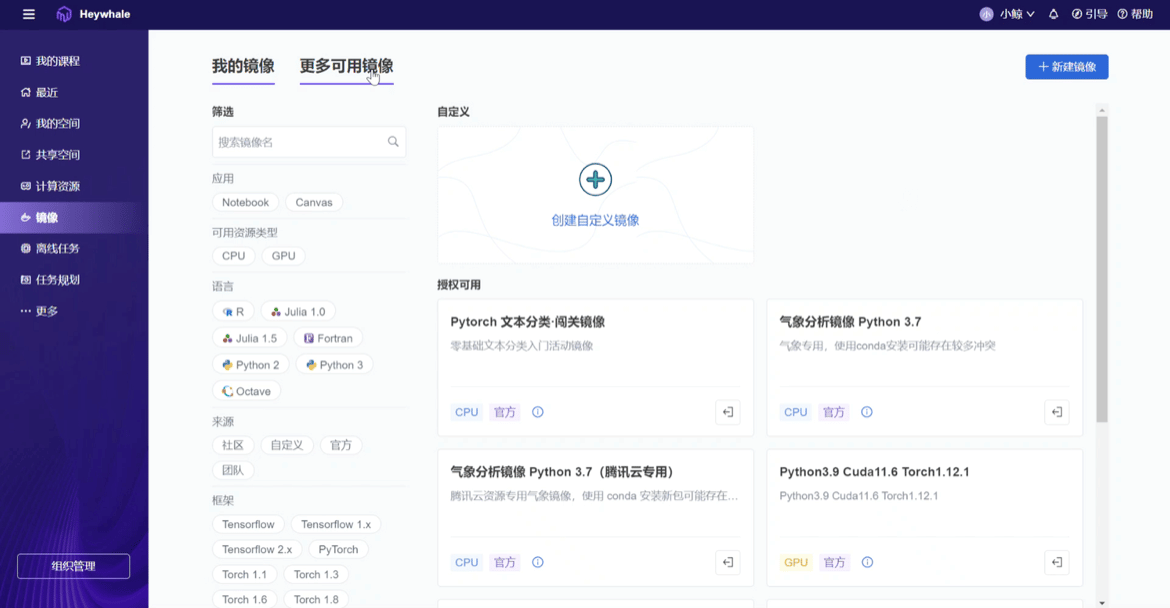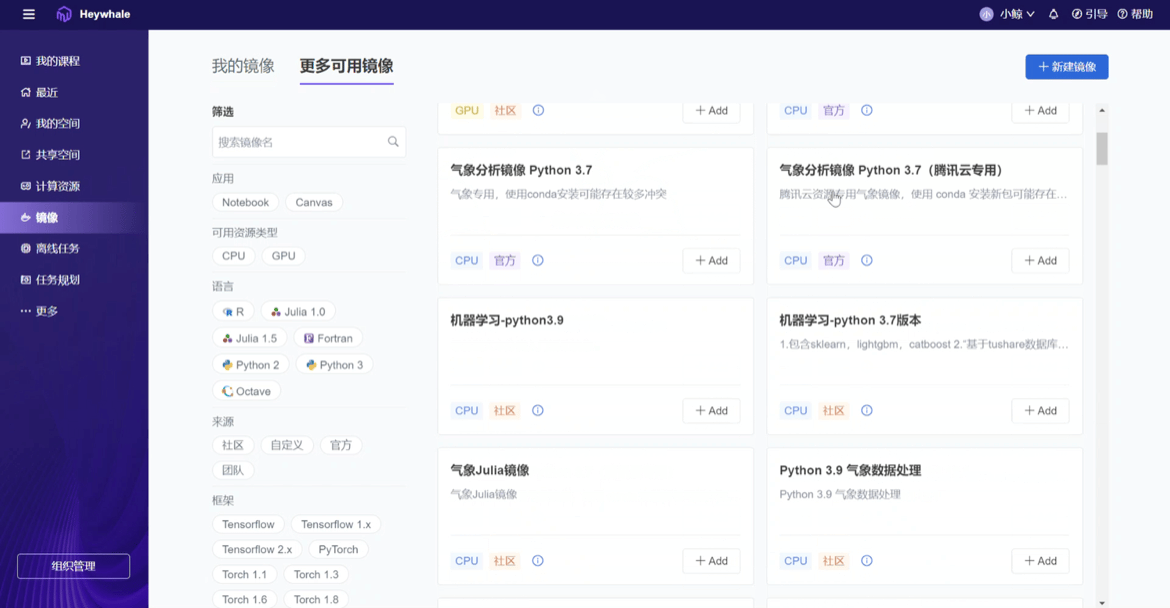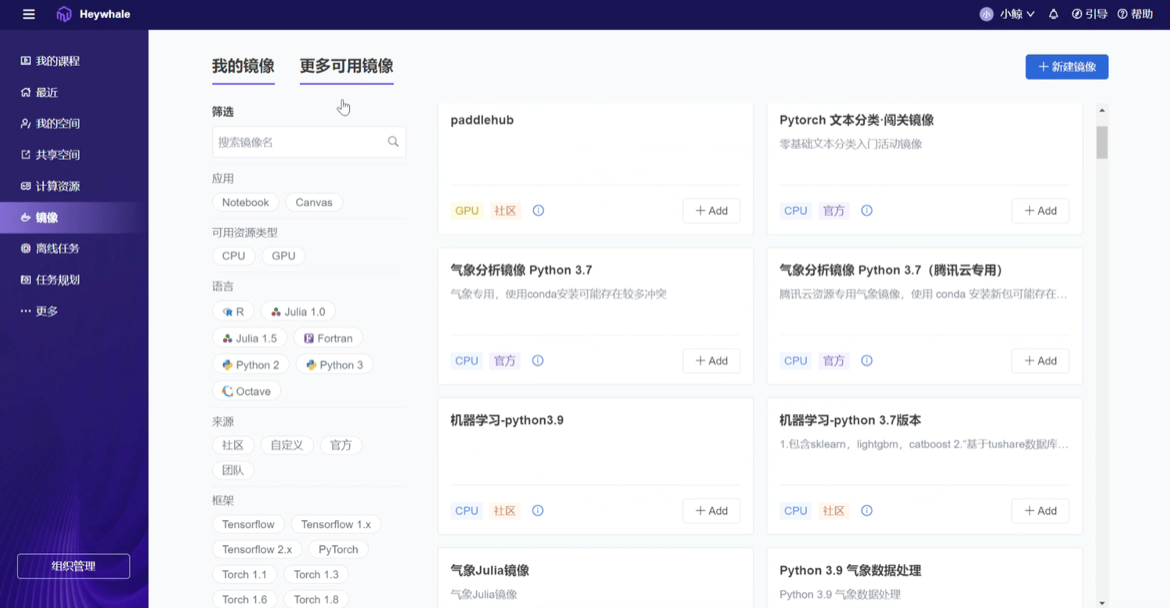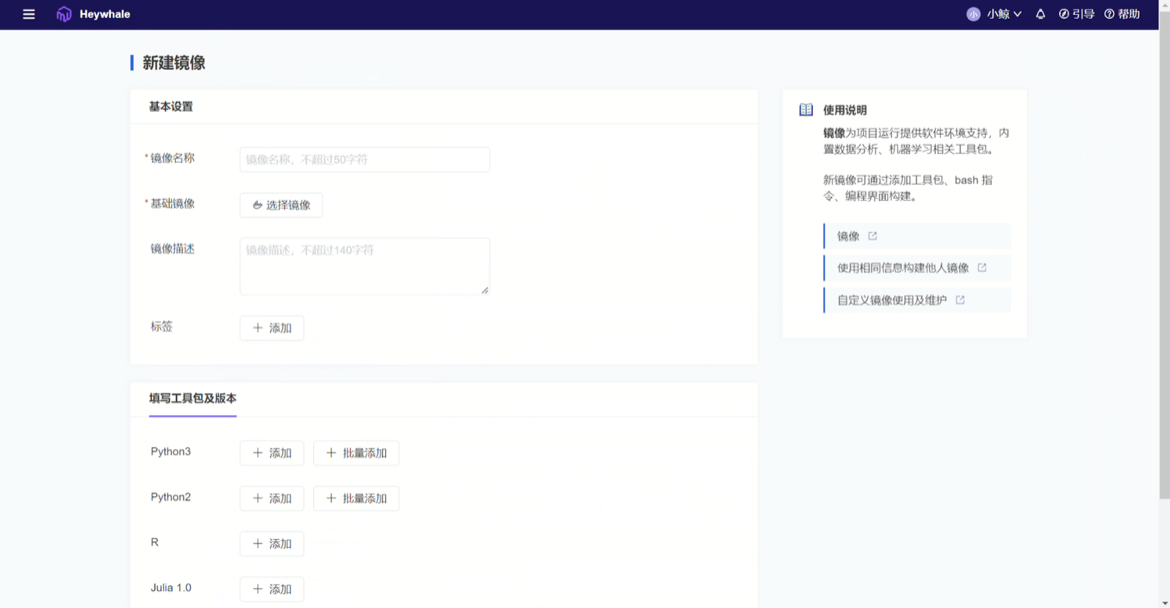
03 版本管理支持非确定性问题探索
配置好环境即可开始数据分析、编程建模。一般的编程操作不必多说,选定相应的分析界面、算力、镜像开始即可。值得一提的是,数据驱动研究一般关注的是对于不确定性问题的探索,面对一个新课题,在最开始,往往并不能够明确哪种方法与手段可达成研究目的,我们需要多种多样的尝试。因此,ModelWhale 在这里能够提供的额外功能就是非 Git 逻辑控制的版本管理,不会太重,随时进行项目的版本比对与 Cell 级版本回溯,支持广大研究者们的从零探索。
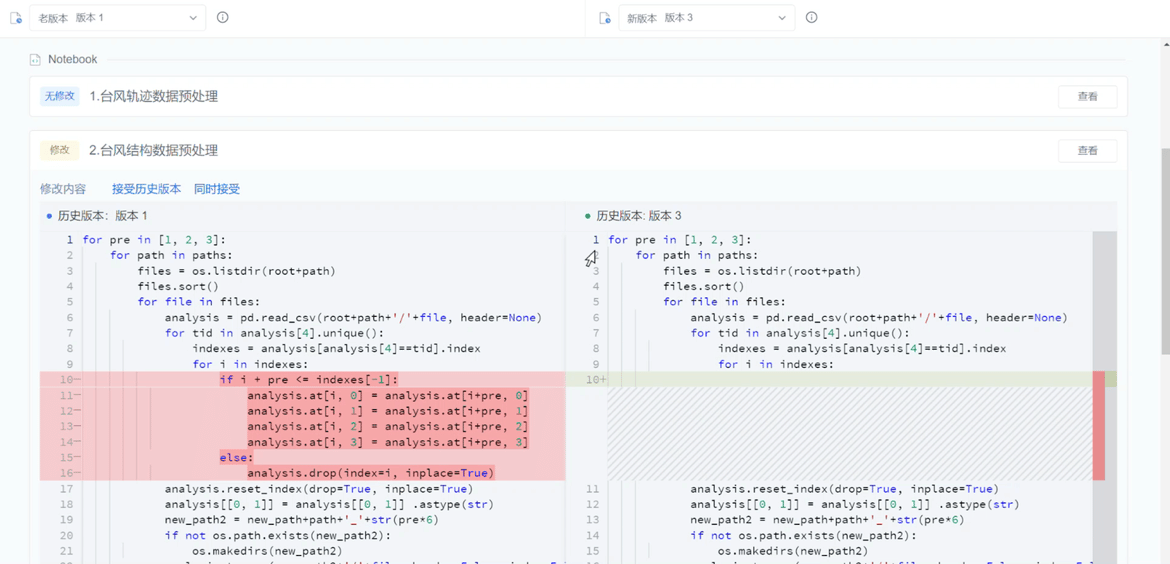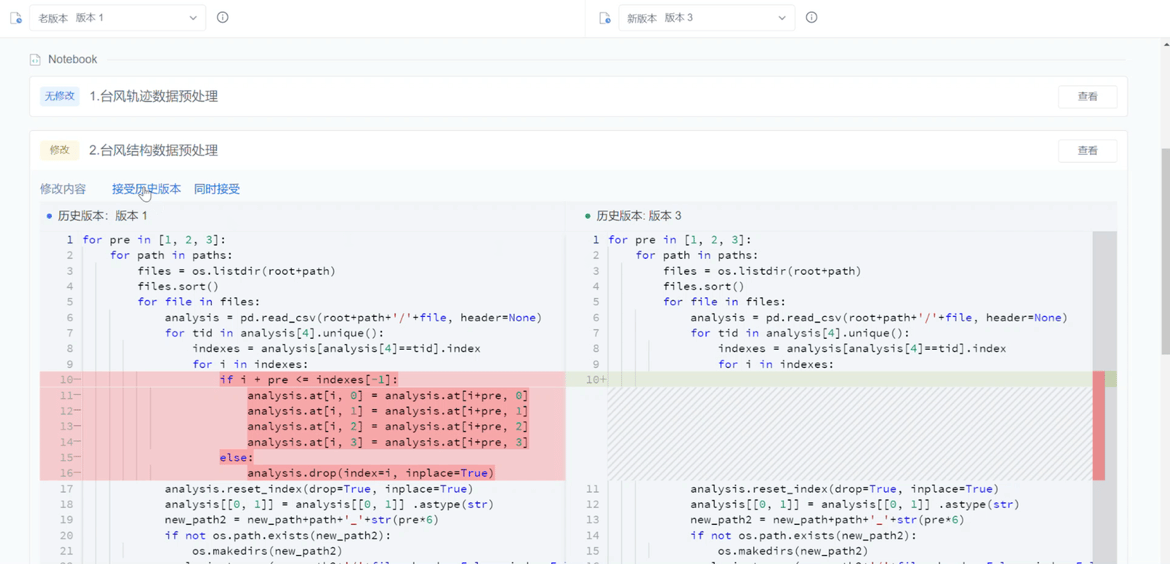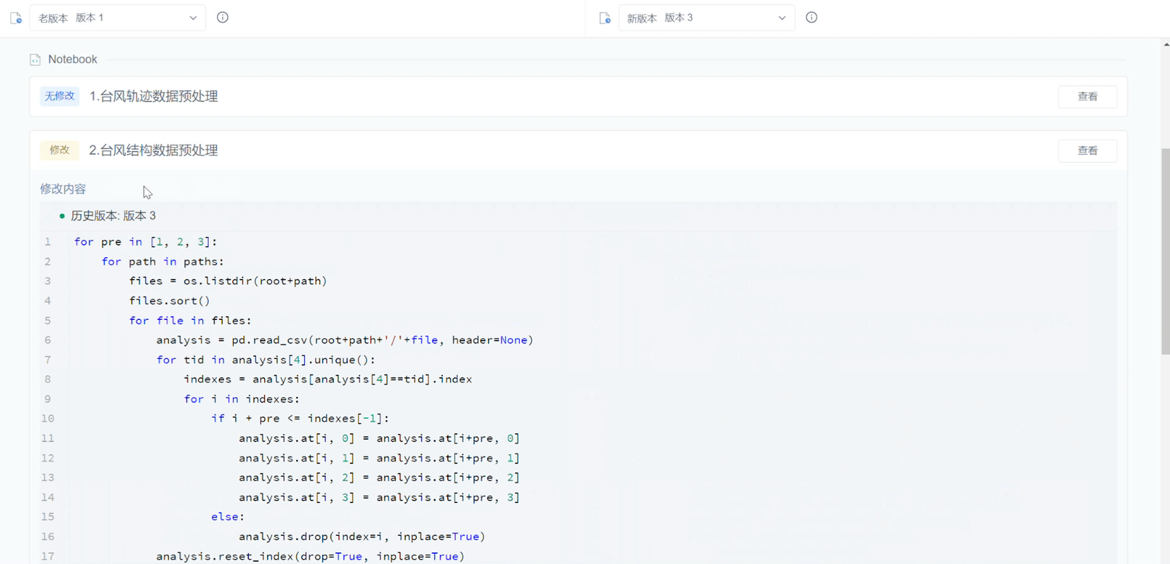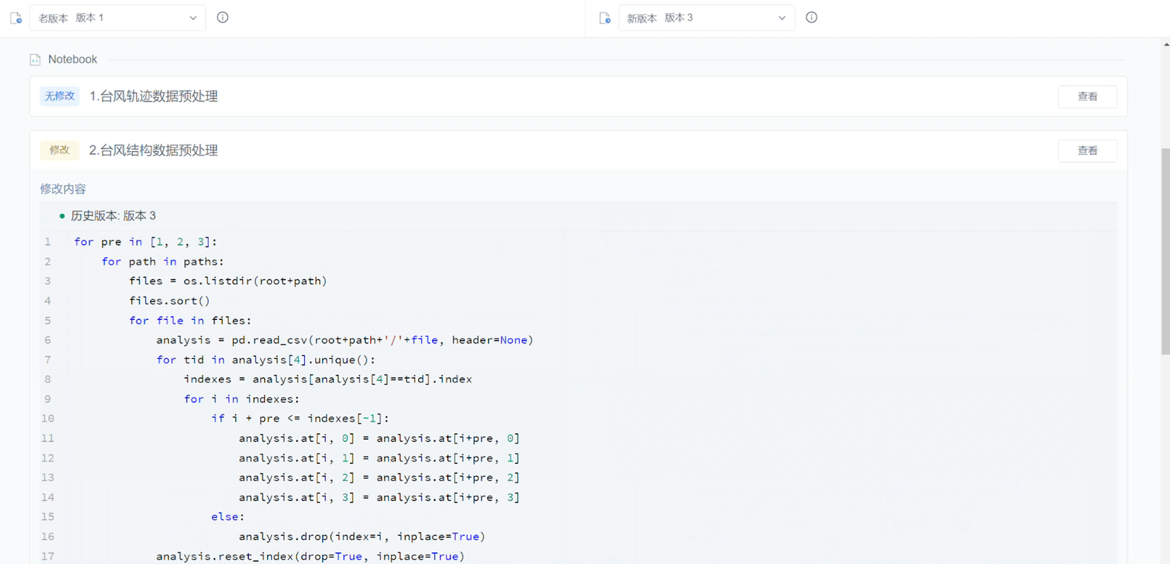
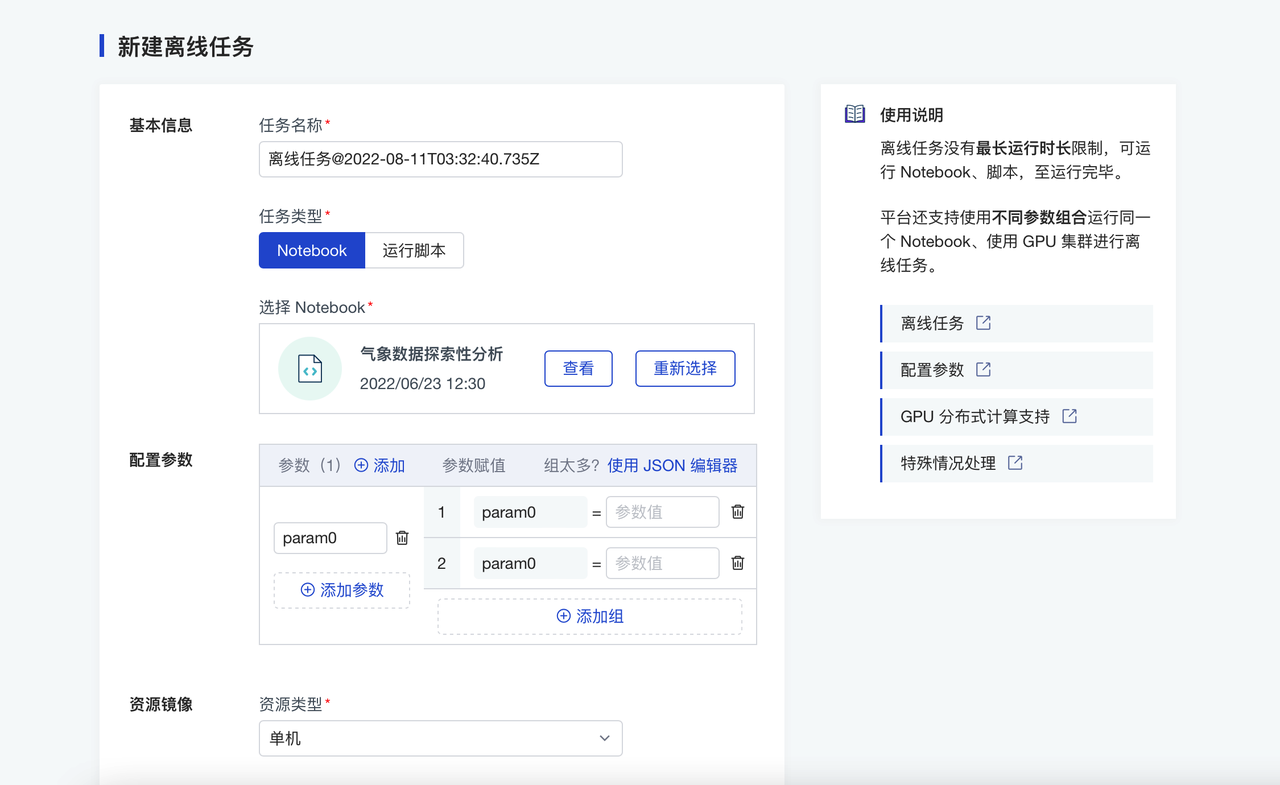
04 模型离线训练:解放精力、资源
另外,针对于数据驱动研究普遍存在的大型复杂计算任务,例如深度学习等,如前文所述,ModelWhale 首先支持将 NAS 目录作为数据源挂载进分析环境,从而实现对超大数据的分析研究,其次还支持模型的离线训练功能,即在电脑关闭后训练任务仍可继续,解放研究人员的时间与精力,同时提供训练结果可视化比对,协助高效进行模型的调参与选择。一句话总结,ModelWhale 将从各种细节缓解研究者们繁复的底层工作。
05 多人协作、团队协同
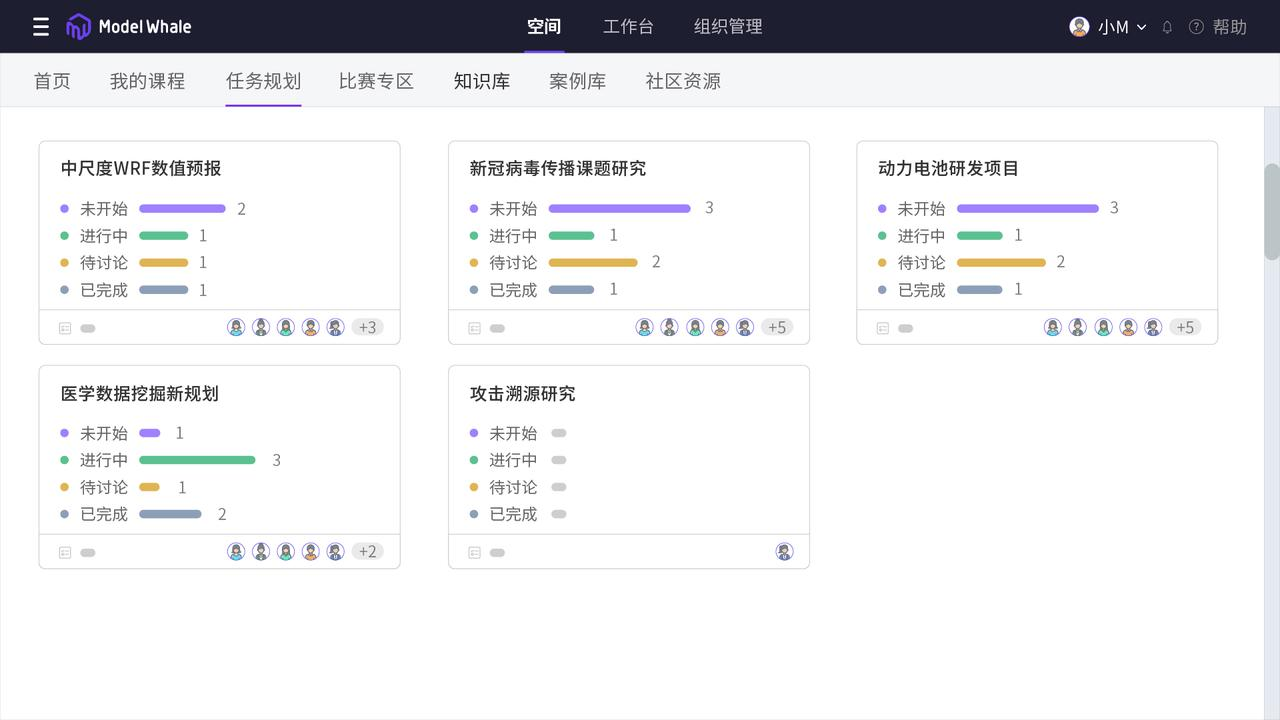
科学研究往往不是一个人的工作,对于复杂项目,组内进行多人分摊是很常有的事,而 ModelWhale 不仅关乎数据科学,更是云端协同创新平台,助力多人协作研究义不容辞。通俗来说,可以将 ModelWhale 想象为代码版的主流云文档软件,能够实现多人在线编辑同个项目,当然,为避免代码碰撞出现的 bug,需要生成版本才能将进展同步给他人。另外 ModelWhale 还具备任务规划的项目管理工具,负责人可以新建课题任务,并将其拆分成子任务进行分发,协同团队共同完成复杂的项目研究。最后,多人协作不仅着眼于某一项目组内部,我们也关注跨行业、跨领域的合作协同:运用 Canvas 功能,代码能力较弱的各领域理论学者可与数据科学家们同时工作,理论学者负责以功能模块搭建研究思路,数据科学家将其转化为实操代码,相辅相成、事半功倍。
复用既往研究
01 复用自定义镜像,不必人人造轮子
ModelWhale 本身内嵌了多种通用与特定学科镜像,新建项目时直接选定即可,那么若这些镜像无法满足当下研究需求又该怎么办呢?这时,研究人员可新建自定义镜像以匹配当前需求。但这并不表示项目组内的每个研究者在开始研究前都需要进行此步操作,一旦完成契合研究需求自定义镜像的新建,该镜像可以分发给组织内的任意成员进行复用,不必人人造轮子,除了负责新建镜像的第一人,组内其他研究者依然能够即开即用地复用既往已被搭建完成的研究环境。
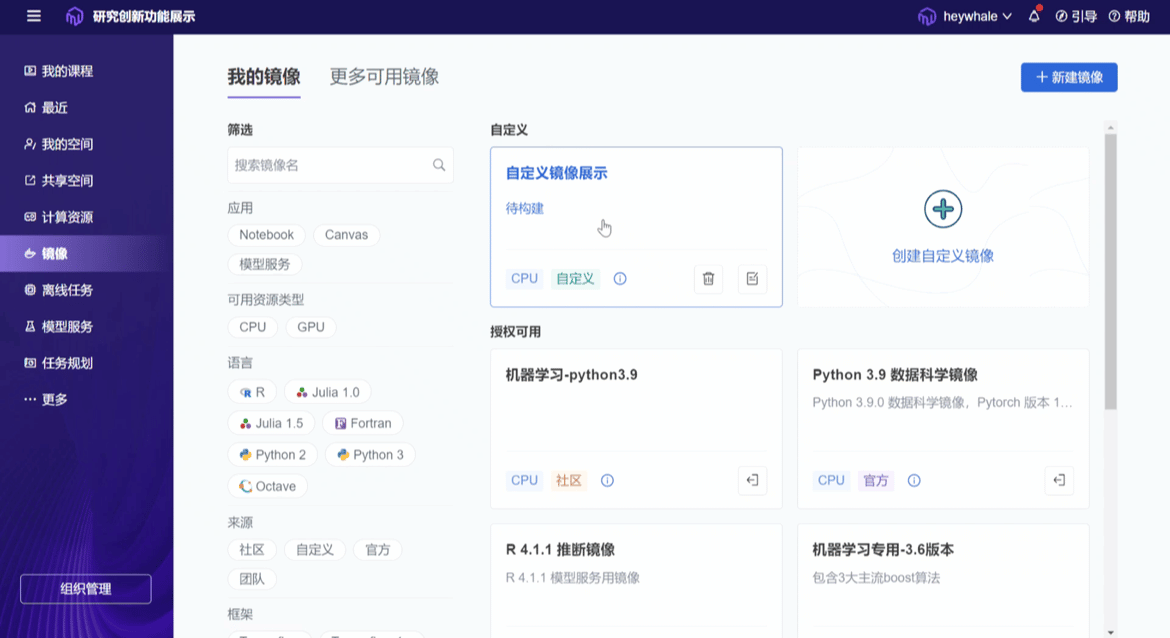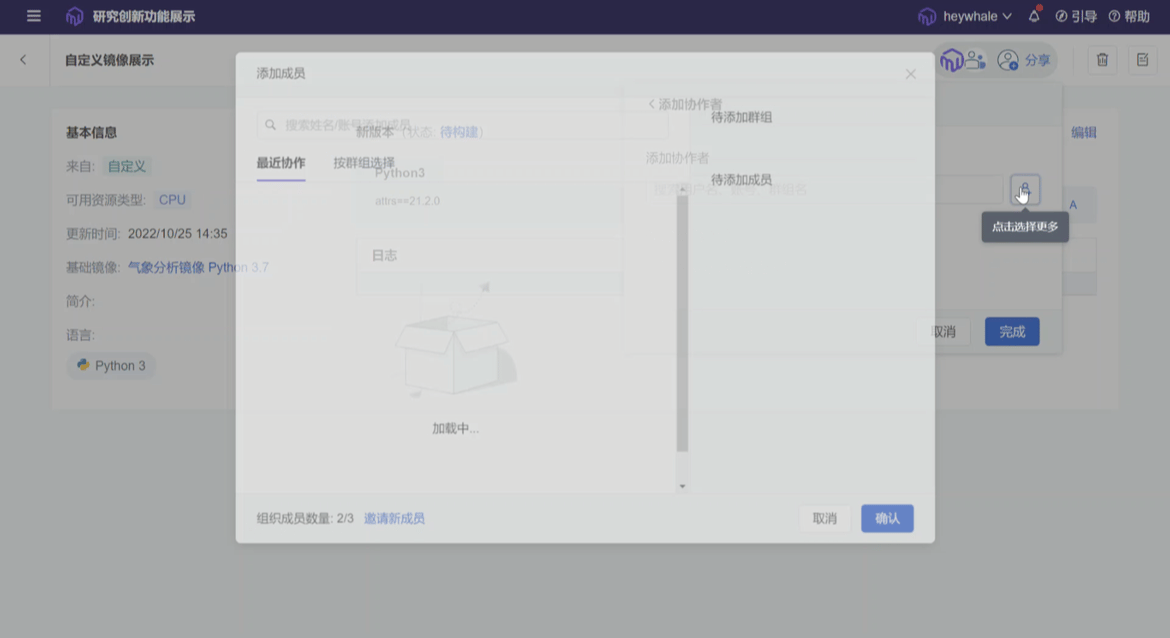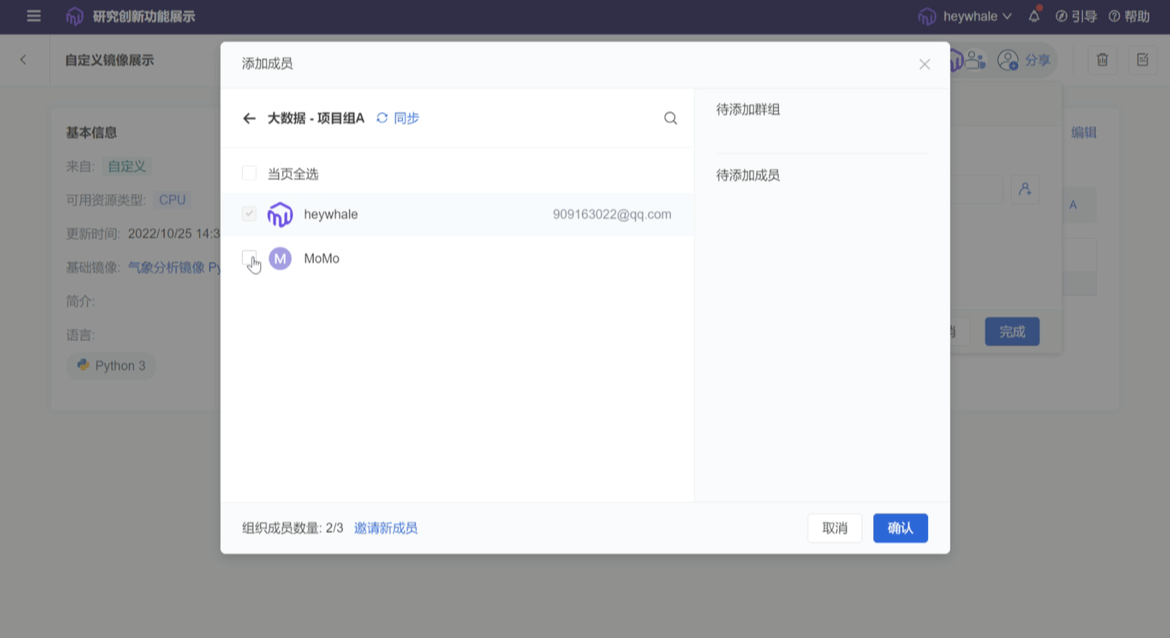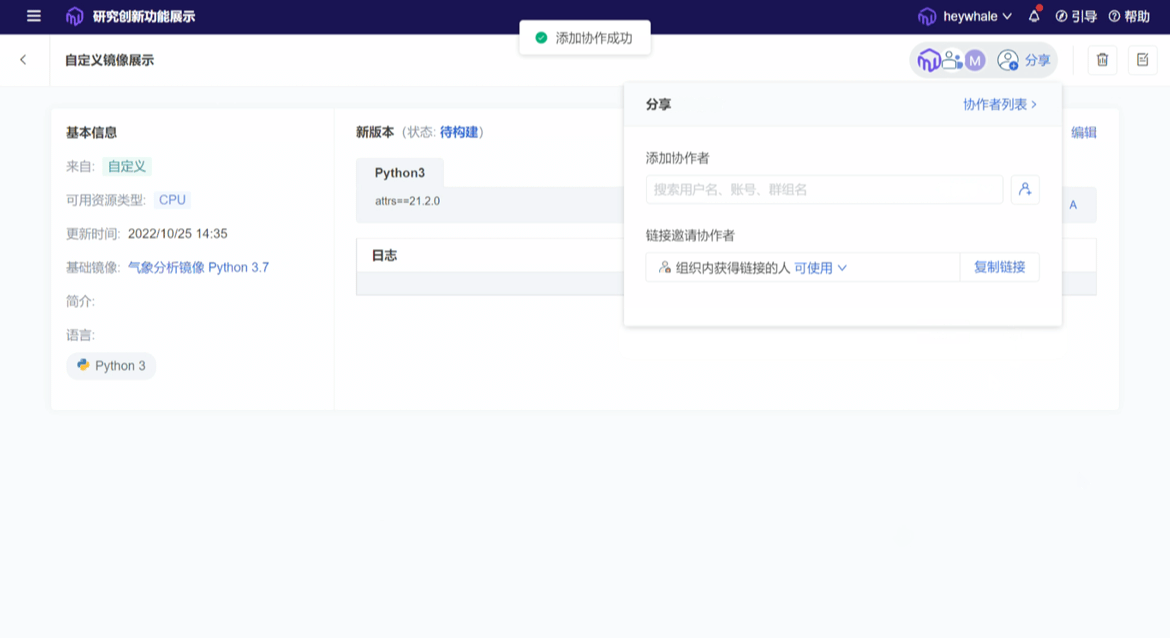
02 Notebook 代码库:代码片段轻松复用
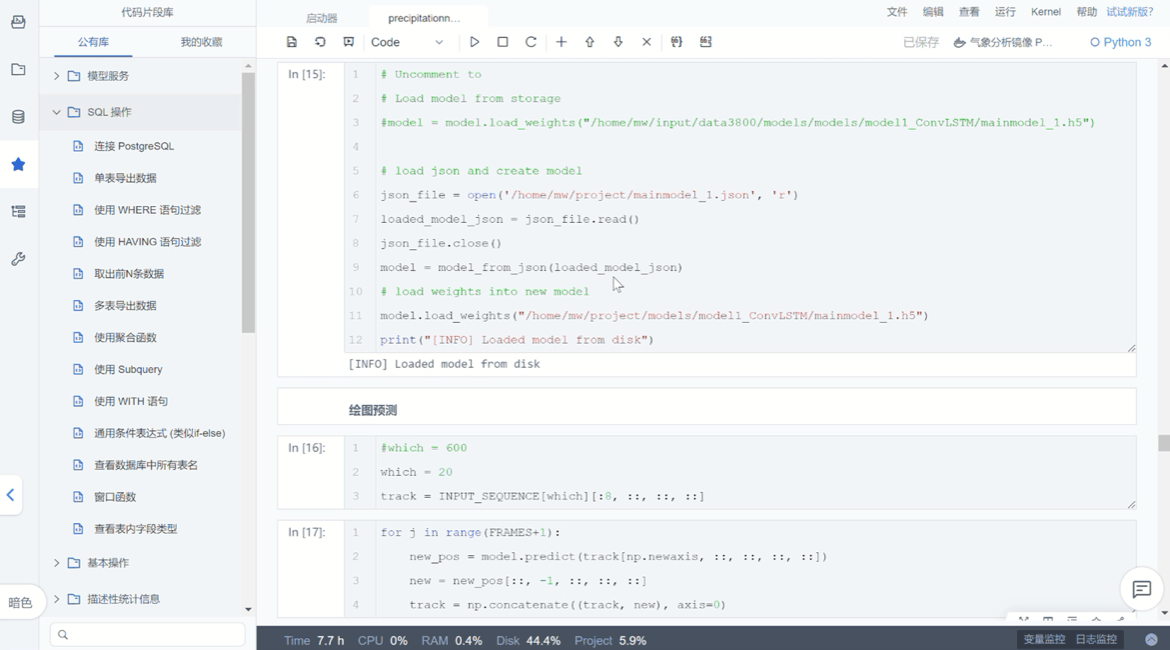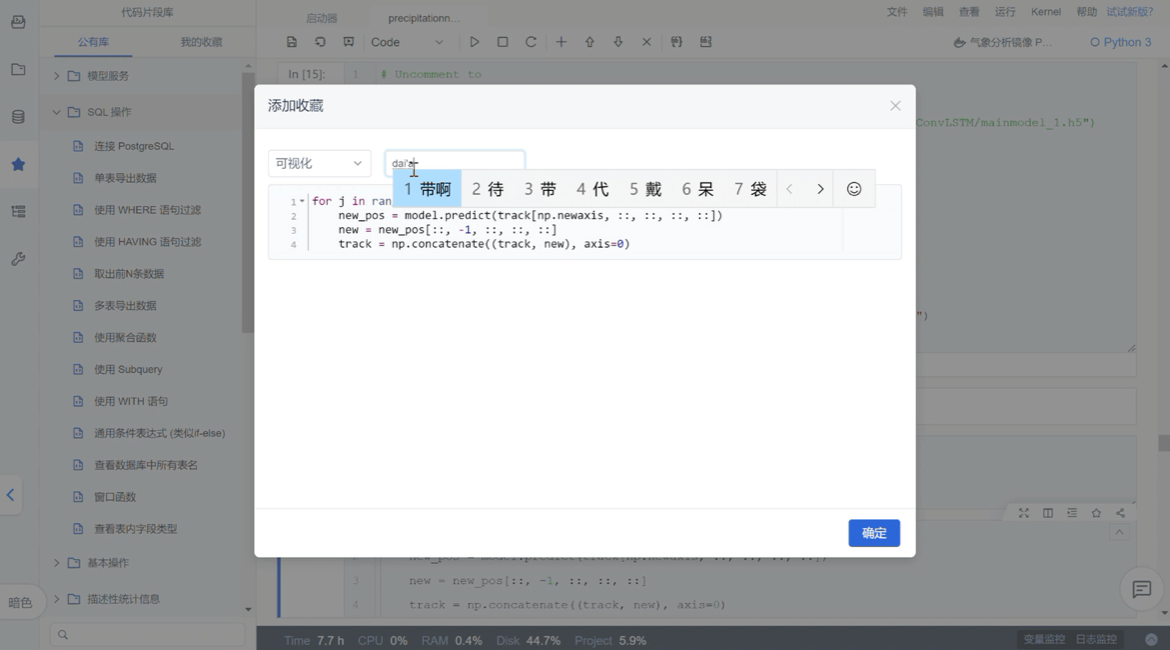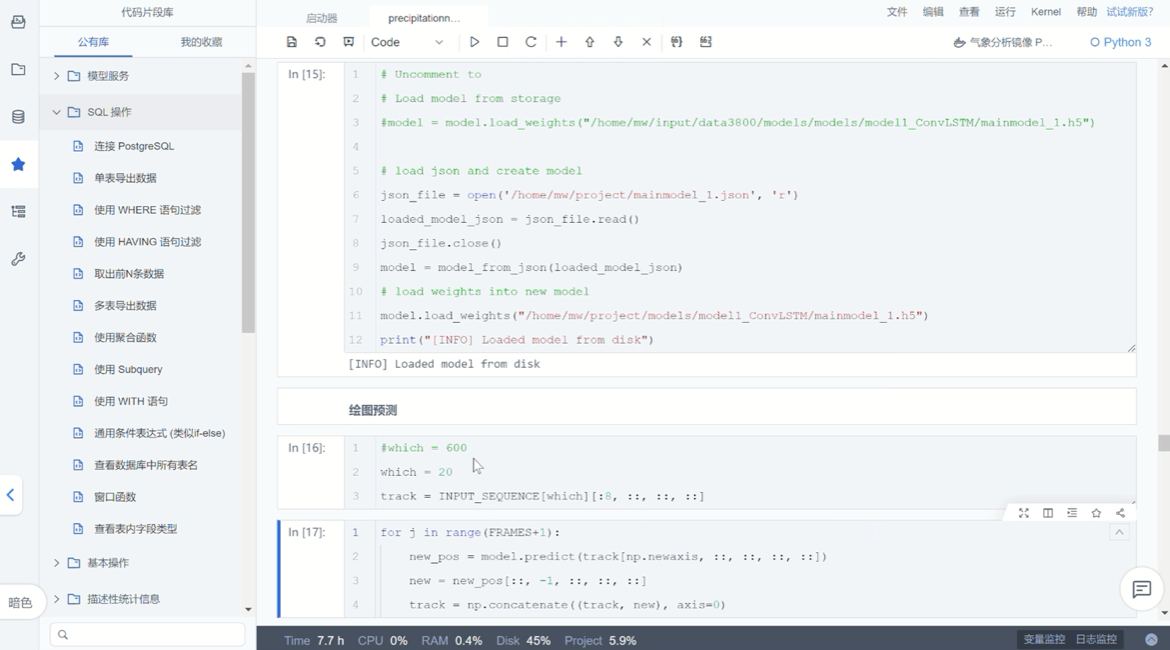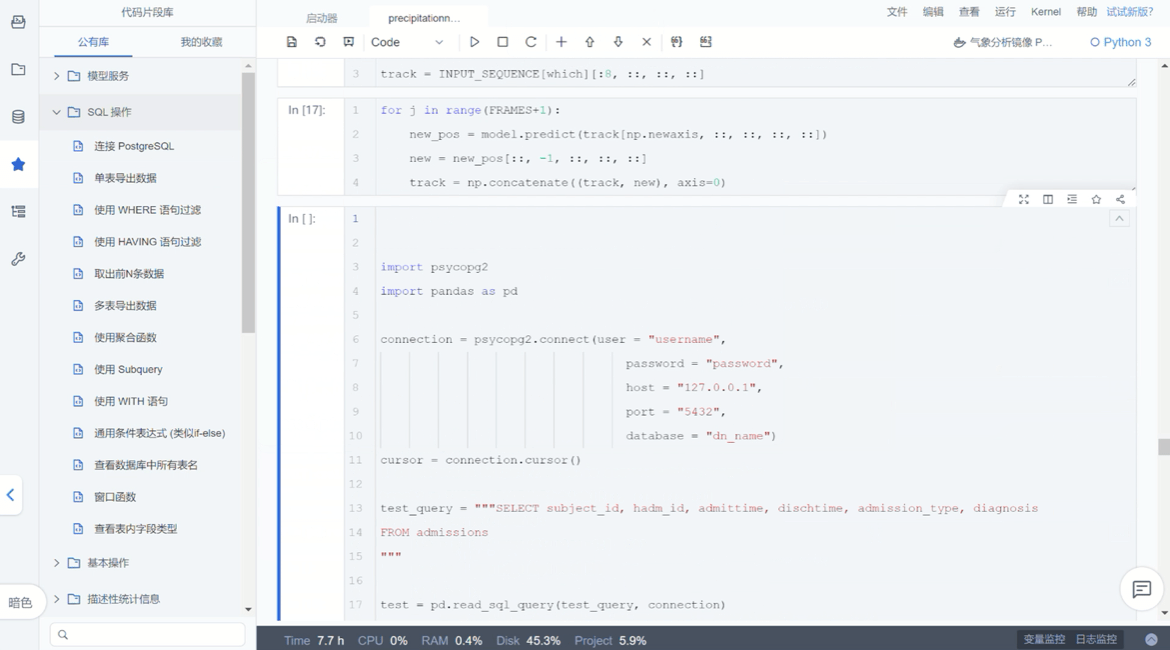
ModelWhale Notebook 侧边栏中具备代码片段库功能,研究人员在既往研究中可预先收藏有几率被复用到的代码片段,后续进行新一轮研究时,即可在该代码库“我的收藏”中找到相应代码片段,此外,代码库中还包含了一部分官方代码,无论是“公有库”还是“我的收藏”,其中的代码片段都能够在新项目界面进行复用,直接插入即可。最后,代码库内的代码片段支持组织内的权限管理与分发,研究人员 A 收藏的代码片段可便捷复用至 B 的项目。
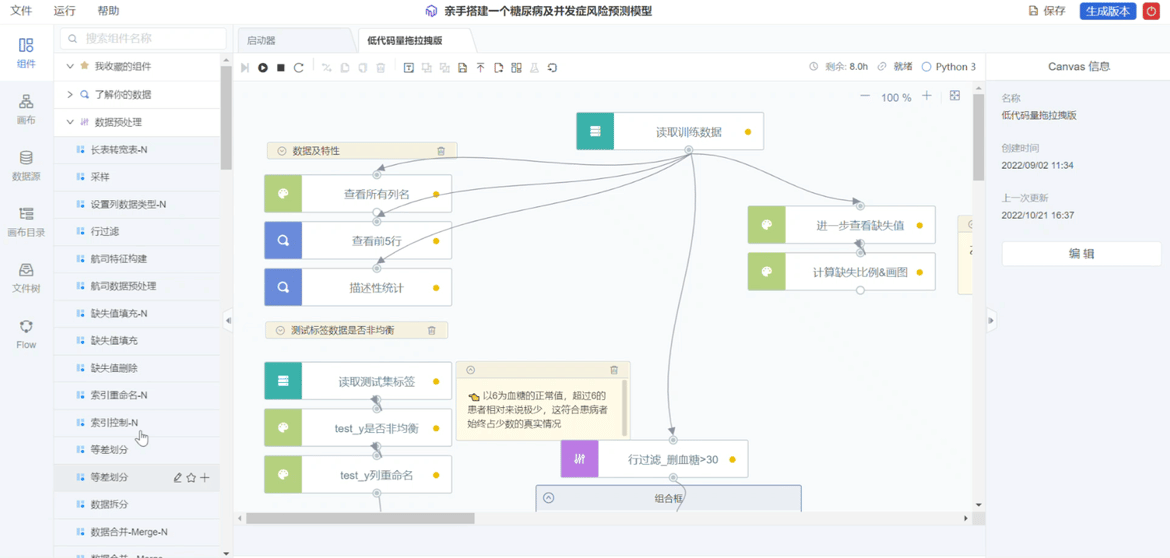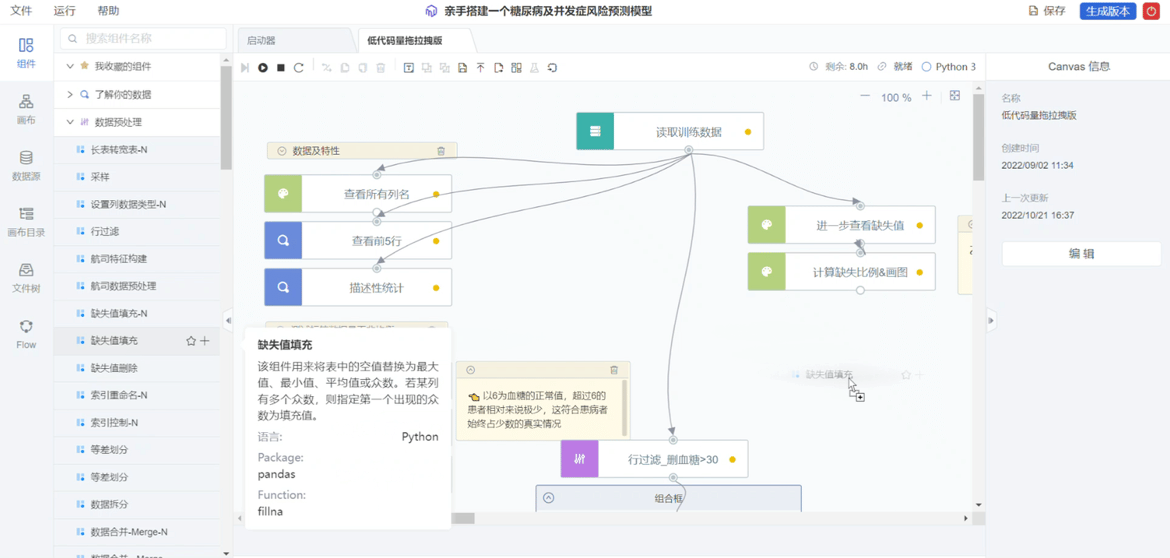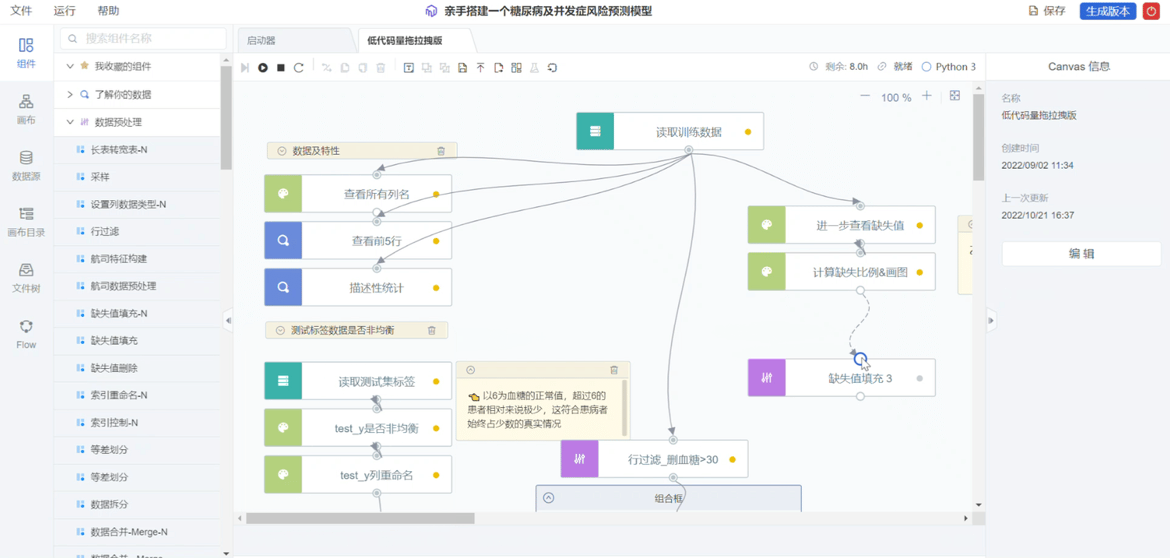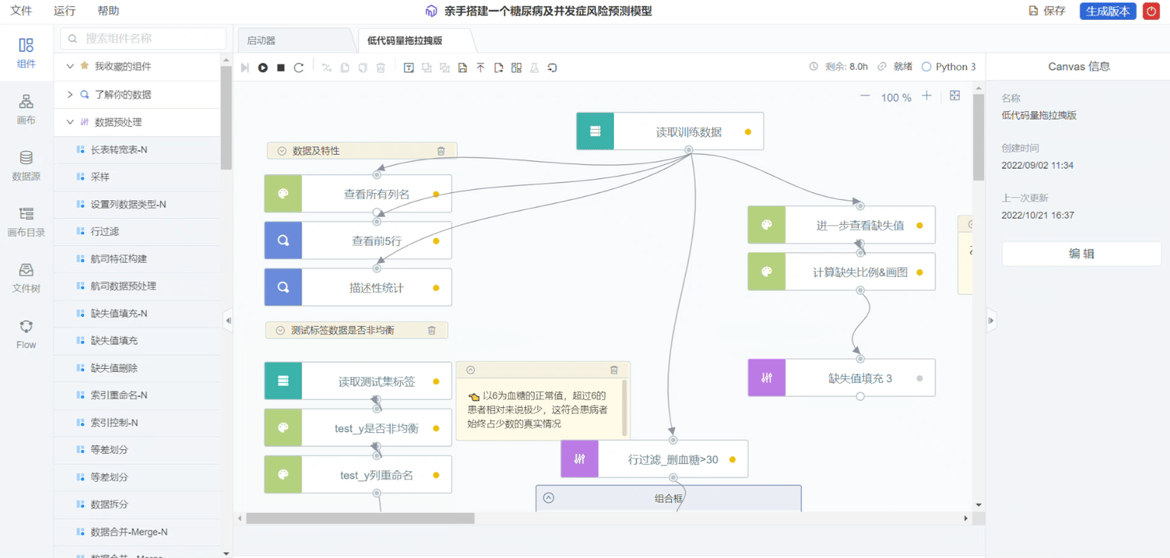
03 Canvas 组件:通过可视化规范 Flow 模板创建项目
ModelWhale Canvas 简单来说是基于可视化和模型驱动的理念,通过“拖拉拽”组件,完成应用模型的搭建。这样说有些大而抽象,实际操作中,Canvas 如何被应用到项目成果的复用过程呢?试想一下,当研究人员正进行一套较为繁琐但极其流程化、不需要创新、后续也还会经常进行的项目步骤时,可选择在 Canvas 中运用组件预构这一套步骤,将其封装成为常用的工作流 Flow,后续在别的项目中再次遇见这一套步骤,就可通过 Canvas 模板直接创建项目、确认组件流程,再转化为 Notebook,此时大框架已有,通过代码微调即可实现那一套繁琐且流程化的项目步骤,十分便捷。

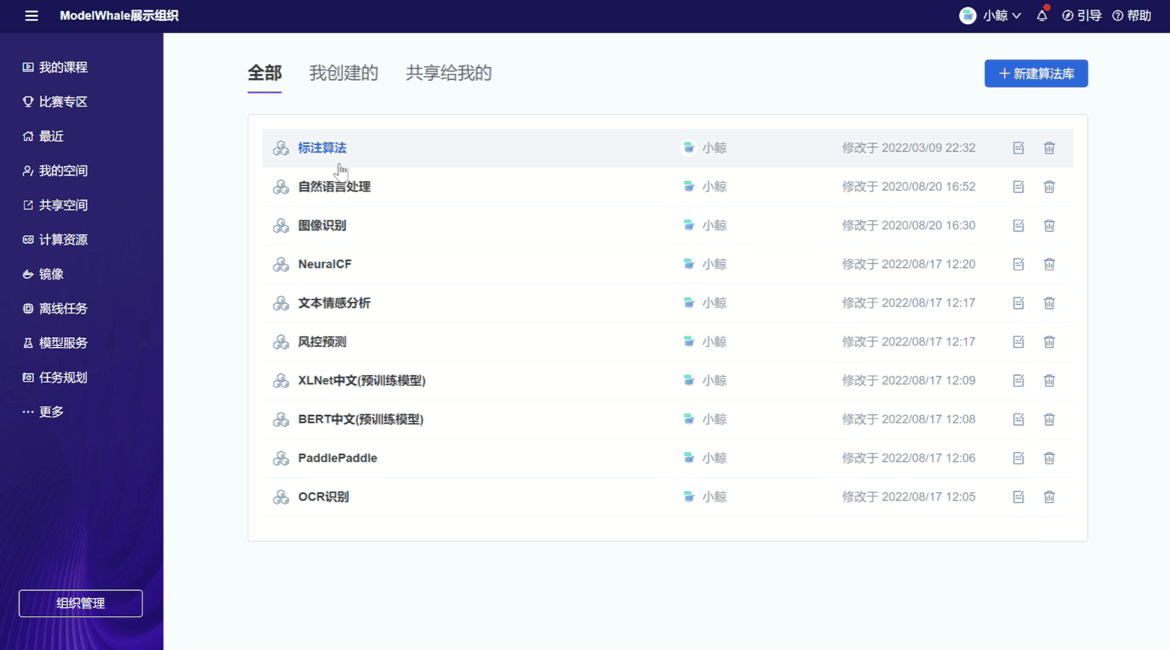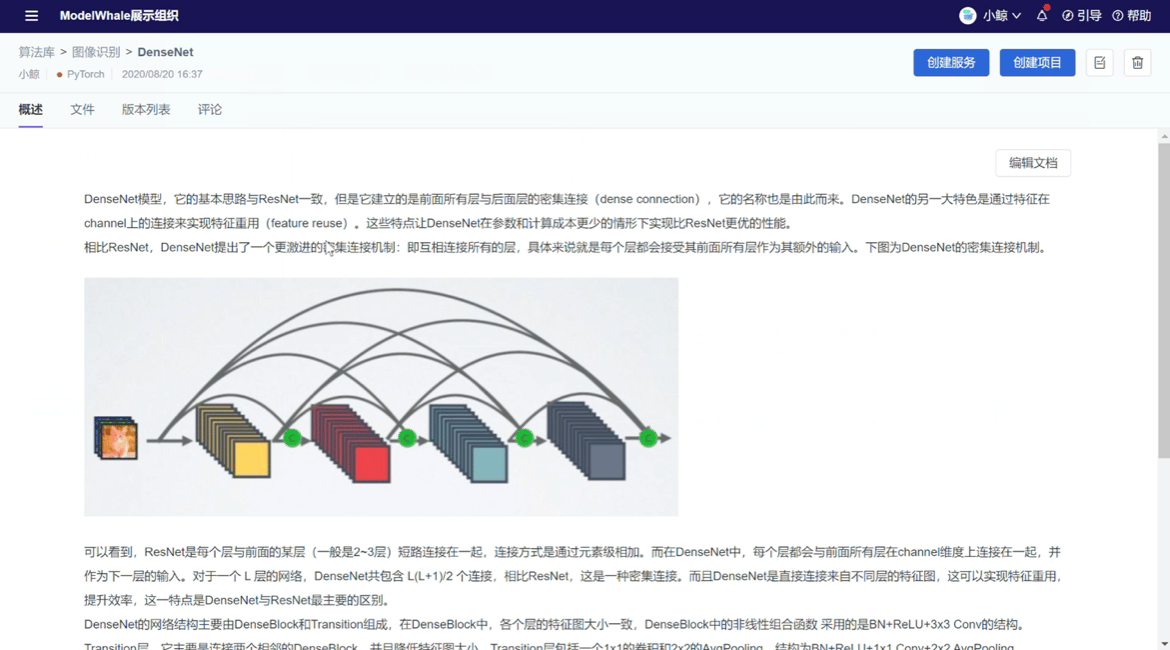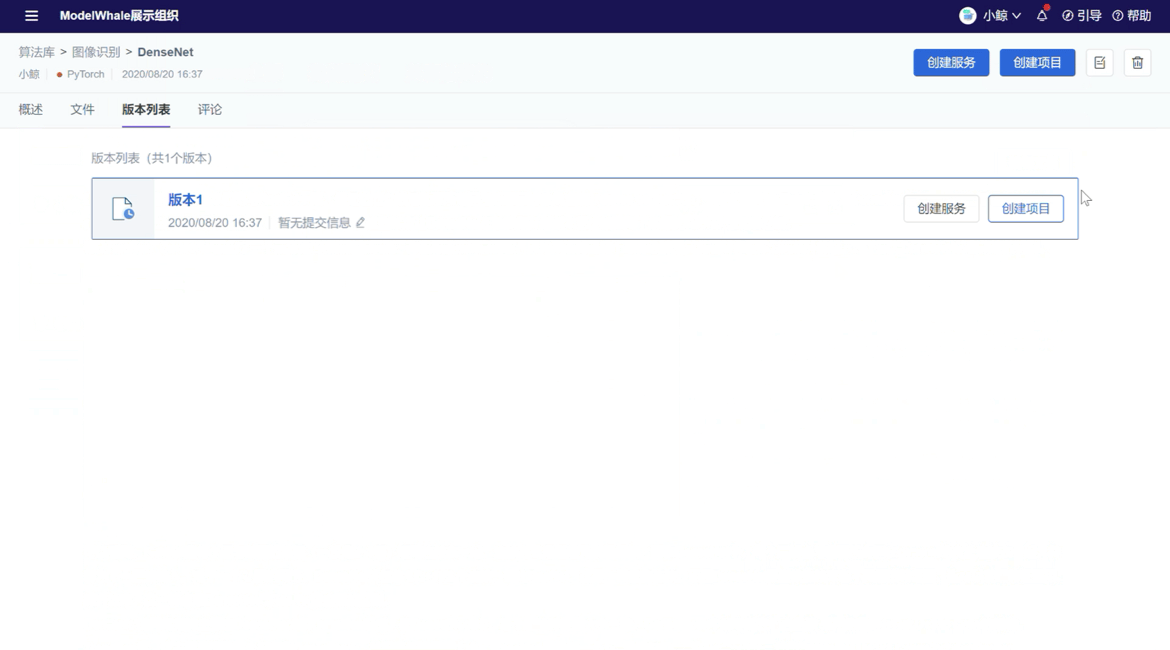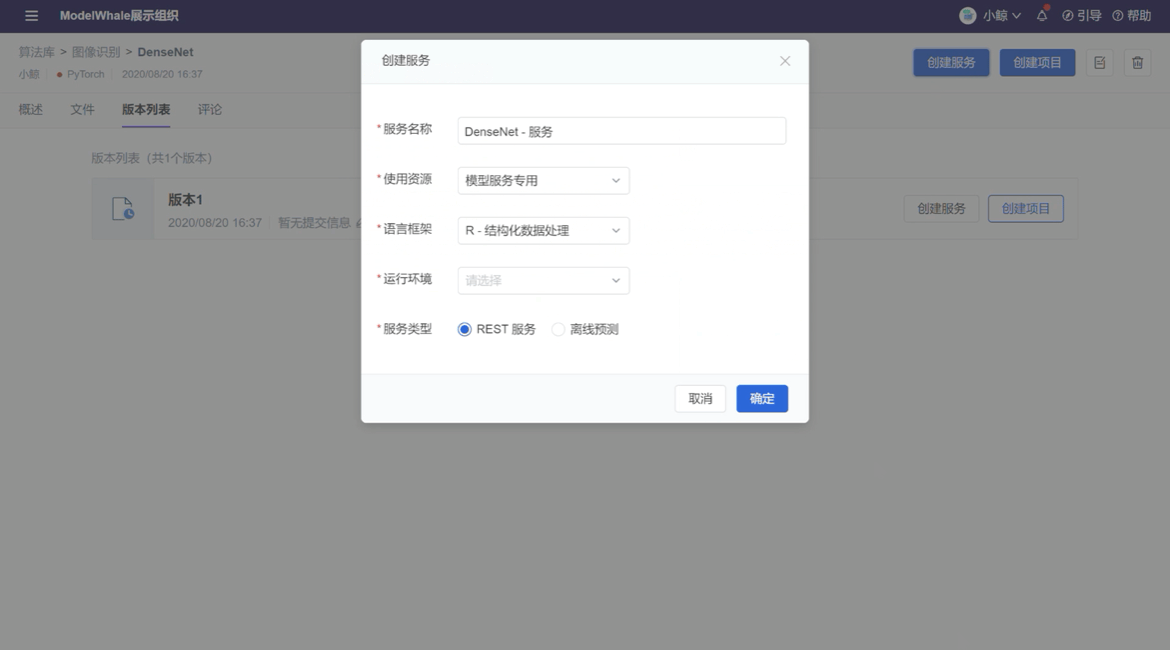
04 算法库:实现对算法模型的整理、分享、复用
利用算法库,研究人员可以管理既往研究工作中已产出的算法模型,辅以文字说明,实现对这些算法模型的整理与分享,实际复用时,可将此类成果直接创建项目或模型服务,免去大量冗余的代码编写、模型训练工作,节省时间。此外,ModelWhale 算法库内也已整理部分常用算法,供研究者在进行通用数据分析工作时随时调用。
三、结束语
在技术革命与顶层政策的引领下,科研界正给予人工智能越来越多的关注。数据科学协同平台 ModelWhale 科研版聚焦数据驱动研究的协同创新,是以推动 AI for Science 科研范式改革、加强有组织科研为己任的数字化基础设施:关注从数据、算法到模型等研究对象的一站式全流程管理,从基础设施层面提升科学研究的可复现性,帮助营造协作协同的良好科研生态;基于 FAIR 原则与开放科研理念为数据等研究生产资料提供安全、完善的公开共享门户与在线交互工作台;异构融合、集约管控、按需分配、敏捷响应,强大的算力调度管理使个人电脑调用 LLM 大语言模型成为可能,也使算力资源在组织团队内发挥最大可用性;引入 ModelOps 理念,助力大模型全生命周期管理。
ModelWhale 科研版覆盖地球科学、生物医学、人文社科等专业领域,且已将最佳实践落实于国家气象信息中心、中国自然资源航空物探遥感中心等国家级科研机构,希望能为每一位从事数据创新研究的开拓者及其团队提供支持。任何相关需求,都欢迎您进入 ModelWhale 官网 注册体验,或点击【联系产品顾问(移动端跳转)】与我们展开交流。